
rainbowchat是一套基于开源im聊天框架 的产品级移动端im系统。rainbowchat源于真实运营的产品,解决了大量的屏幕适配、细节优化、机器兼容问题(可自行下载体验:)。
* rainbowchat可能是市面上提供im即时通讯聊天源码的,唯一一款同时支持tcp、udp两种通信协议的im产品(通信层基于开源im聊天框架 实现)。
► 详细产品介绍:
► 版本更新记录:
► 全部运行截图:、
► 在线体验下载:、 (关于 ios 端,请:)
blogjava-凯发k8网页登录

mobileimsdk 是一套专门为移动端开发的开源im即时通讯框架,超轻量级、高度提炼,一套api优雅支持udp 、tcp 、websocket 三种协议,支持ios、android、h5、小程序、uniapp、标准java平台,服务端基于netty编写。
工程开源地址是:
- 1)gitee码云地址:
- 2)github托管地址:
此版更新内容():
(1)android端主要更新内容:
- 1)[bug] 解决了app从后台恢复时,有一定几率因后台多线程操作好友数据导致的线程安全崩溃问题;
- 2)[优化] 加固了一处好友列表中根据昵称取拼音首字母的非空检查逻辑;
(2)服务端主要更新内容:
- 1)[bug] 升级了mobileimsdk至v6.5,尝试解决极小几率下android端会误把“自已”踢掉的问题
- 2)[bug] 解决了因netty库版本升级导致ios消息推送失败报错的问题:
- 3)[bug] 解决了消息撤回时,被引用消息的历史记录没有正确处理撤回逻辑;
- 4)[优化] 为“接口1008-26-7”增加了“at_me”字段的返回;
- 5)[优化] 优化了“接口1008-26-8”,使得在跟web互通时支持按时间戳的聊天记录分页加载方案;
- 6)[优化] 为“接口1008-26-8”增加了“消息发送者昵称”内容的返回;
部分功能运行截图():
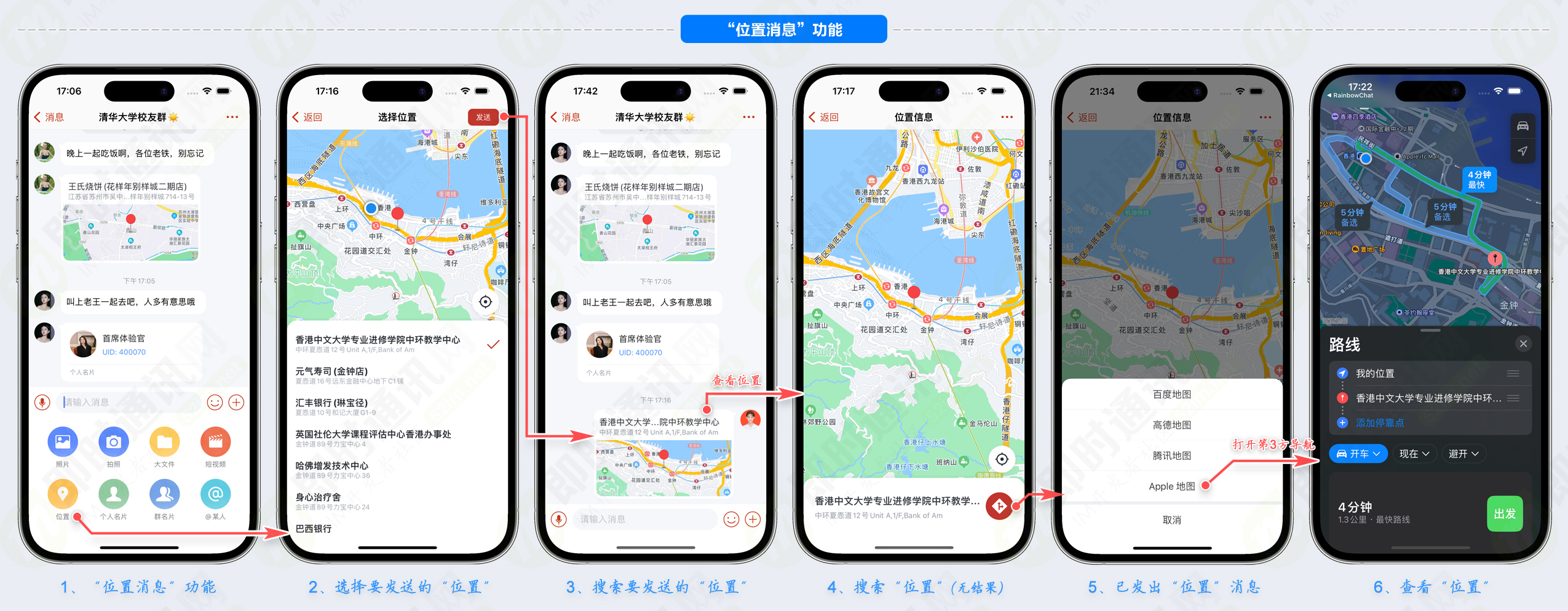
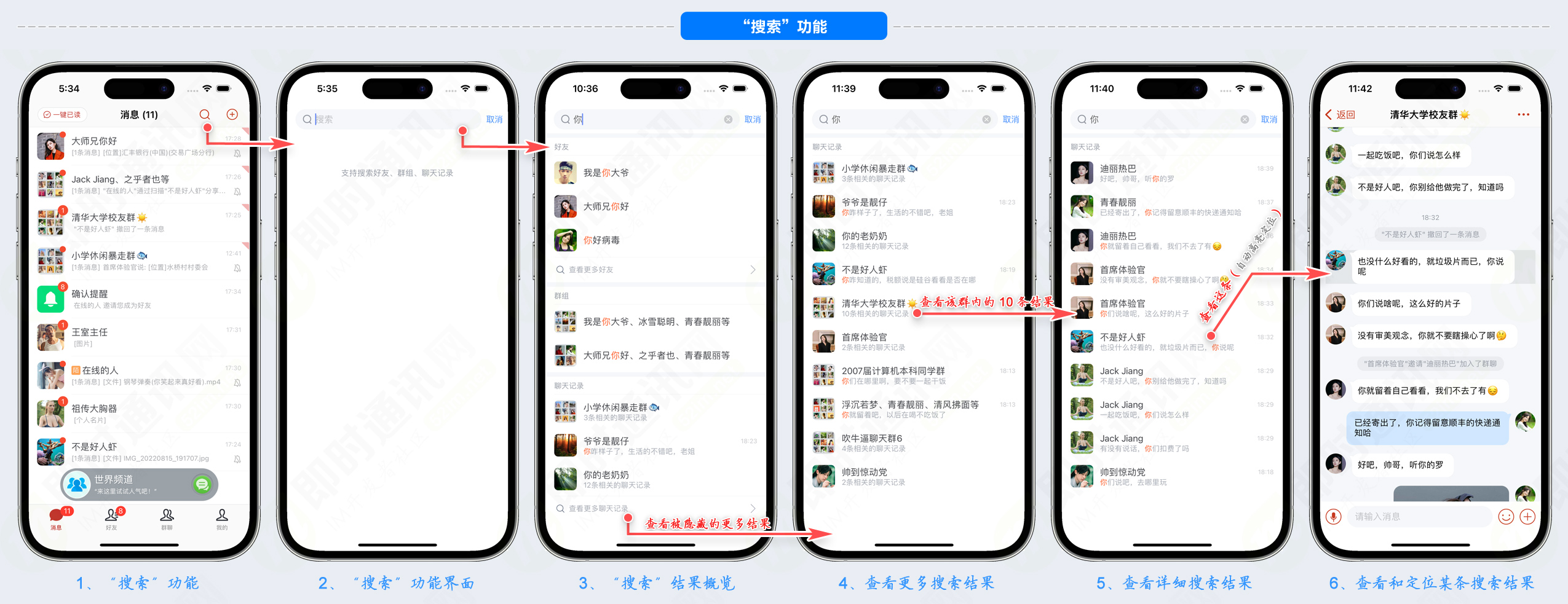
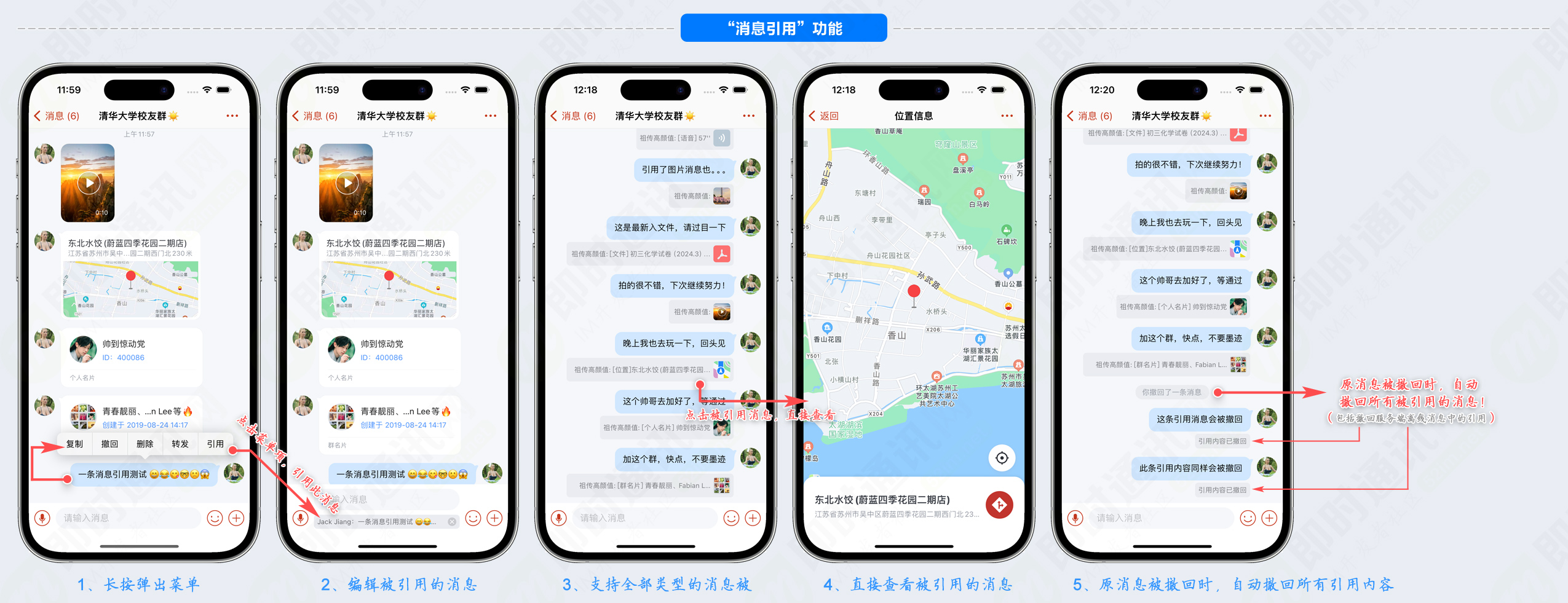

是一套web网页端im系统,是的姊妹系统(rainbowchat是一套基于开源im聊天框架 () 的产品级移动端im系统)。
此版更新内容():
- 1)[bug] [前端] - 解决了转发语音消息后,语音消息ui气泡css样式问题;
- 2)[bug] [前端] - 解决了登陆后首次打开对应聊天界面前收到的新消息和历史消息显示顺序问题;
- 3)[bug] [前端] - 解决了删除聊天后,没有自动清除聊天界面上的“加载更多”功能按钮;
- 4)[bug] [前端] - 解决了引用陌生人消息时,显示的是uid而不是对方昵称的问题;
- 5)[bug] [前端] - 解决了群主撤回群员消息时,系统通知中显示的是uid而不是对方昵称的问题;
- 6)[优化] [前端] - 优化了引用的消息内容中表情图标导致引用的文字不能垂直居中显示的ui问题;
- 7)[优化] [前端] - 优化了群聊中消息发送者昵称的显示;
- 8)[优化] [服务端] - 为“接口1008-26-8”增加了“消息发送者昵称”内容的返回;
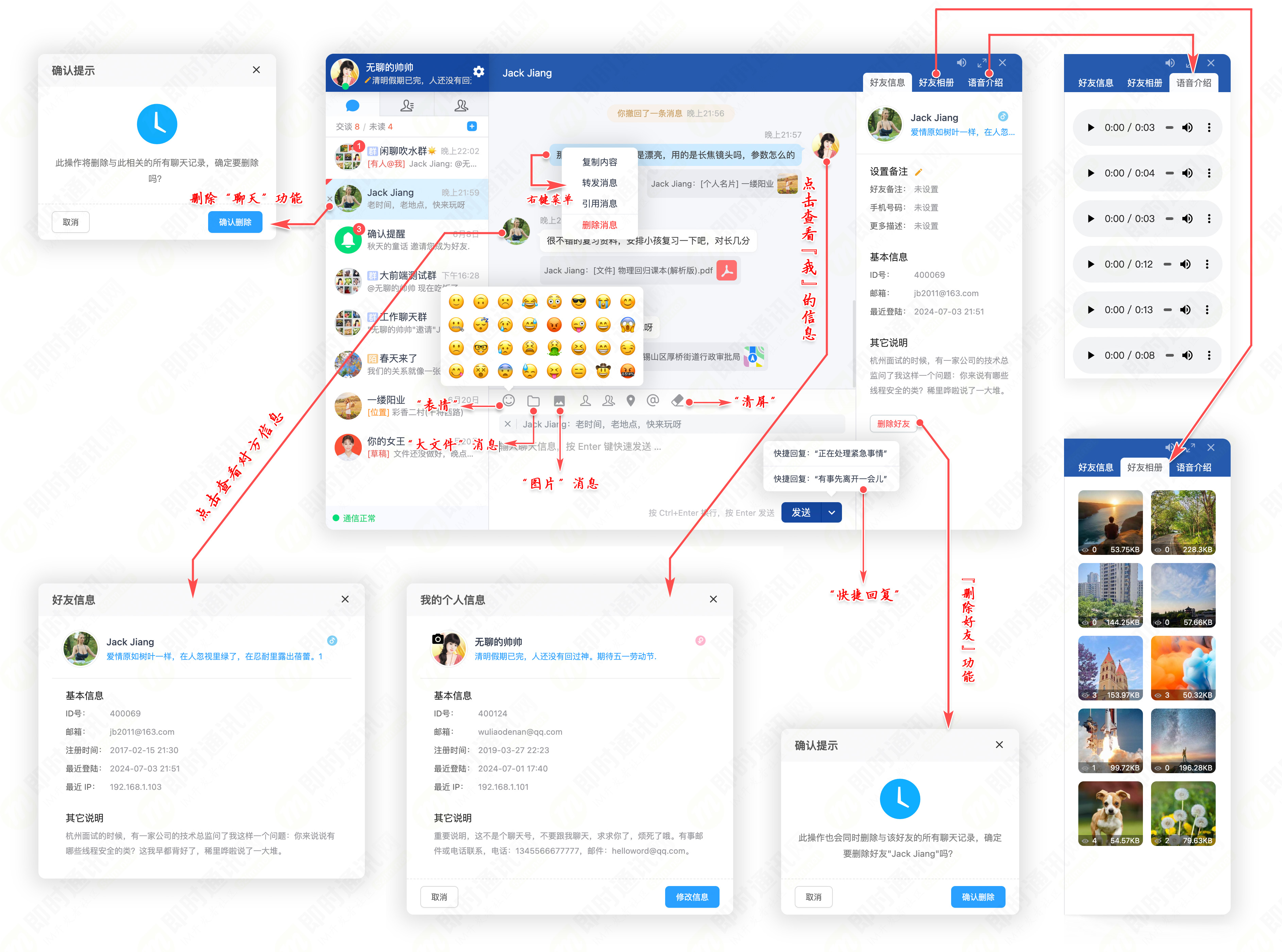
主要功能特性截图(、):
1.生成ssh-key
#会产生 ~/.ssh/id_rsa 和 ~/.ssh/id_rsa_pub 文件
2.在github上新建仓库
3.导入公钥到github
4.克隆仓库
git config --global user.email johndoe@example.com
5.导入project到eclipse
]]>
为了更好地分类阅读 52im.net 总计1000多篇精编文章,我将在每周三推送新的一期技术文集,本次是第41 期。
[- 1 -]
[链接]
[摘要] 本文是《移动端实时音视频直播技术详解》系列文章之第一篇,我们将从整体介绍直播中的各个环节。
[- 2 -]
[链接]
[摘要] 本文是《移动端实时音视频直播技术详解》系列文章之第二篇:我们将从整体介绍直播中的采集环节。
[- 3 -]
[链接]
[摘要] 本篇是《移动端实时音视频直播技术详解》系列文章之第三篇:我们将从整体讲解常见视频处理功能:如美颜、视频水印、滤镜、连麦等。
[- 4 -]
[链接]
[摘要] 本篇是是《移动端实时音视频直播技术详解》系列文章之第四篇:我们将从整体讲解编码和封装。
[- 5 -]
[链接]
[摘要] 本篇是《移动端实时音视频直播技术详解》系列文章之第五篇:我们将从整体讲解推流和传输。
[- 6 -]
[链接]
[摘要] 本篇是《移动端实时音视频直播技术详解》系列文章之第六篇:我们将从整体讲解延迟优化技术。
[- 7 -]
[链接]
[摘要] 本次分享就向大家介绍一下分享一下直播的整个流程和一些技术点,并动手实现一个简单的demo。
[- 8 -]
[链接]
[摘要] 连麦视频直播的客户端主要包括:原生 app、浏览器 h5、浏览器 webrtc、微信小程序。浏览器上的应用包括 h5 和 webrtc,前者可以拉流观看,后者可以实现推流和拉流。
[- 9 -]
[链接]
[摘要] 实时视频直播是这两年非常火的技术形态,已经渗透到教育、在线互娱等各种业务场景中。但要搭建一套实时视频直播系统,并非易事,当然相关的直播技术理论在论坛的其它文章里已经写的非常详细,本文不再展开。
[- 10 -]
[链接]
[摘要] 本文由淘宝直播音视频算法团队分享,对实现高清、低延时实时视频直播技术进行了较深入的总结,希望分享给大家。
[- 11 -]
[链接]
[摘要] 直播行业的竞争越来越激烈,进过2018年这波洗牌后,已经度过了蛮荒暴力期,剩下的都是在不断追求体验。最近正好在做直播首开优化工作,实践中通过多种方案并行,已经能把首开降到500ms以下,借此机会分享出来,希望能对大家有所启发。
[- 12 -]
[链接]
[摘要] 本文将分享新浪微博系统开发工程师陈浩在 rtc 2018 实时互联网大会上的演讲。他分享了新浪微博直播互动答题架构设计的实战经验。其背后的百万高并发实时架构,值得借鉴并用于未来更多场景中
👉52im社区本周新文:《》,欢迎阅读!👈
我是jack jiang,我为自已带盐!https://github.com/jackjiang2011/mobileimsdk/
1.设置环境变量,ollama的模型保存路径,/etc/profile
2.克隆ollama代码
3.启动ollama
4.建立ollama镜像的配置文件,modelfile
from /root/.ollama/llamafactory-export/saves/llama3-8b/lora/docker-commnad-nlp/export
# set custom parameter values
parameter temperature 1
parameter num_keep 24
parameter stop <|start_header_id|>
parameter stop <|end_header_id|>
parameter stop <|eot_id|>
parameter stop <|reserved_special_token
# set the model template
template """
{{ if .system }}<|start_header_id|>system<|end_header_id|>
{{ .system }}<|eot_id|>{{ end }}{{ if .prompt }}<|start_header_id|>user<|end_header_id|>
{{ .prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .response }}<|eot_id|>
"""
# set the system message
system you are llama3 from meta, customized and hosted @ paul wong (http://paulwong88.tpddns.cn).
# set chinese lora support
#adapter /root/.ollama/models/lora/ggml-adapter-model.bin
cd $bin_path/
pwd
ollama create llama3-docker-commnad-nlp:paul -f modelfile
5.运行大模型
]]>
1.克隆并安装llama factory库,install-llamafactory.sh
cd $bin_path/../
pwd
git clone --depth 1 https://github.com/hiyouga/llama-factory.git
cd llama-factory
pip install -e ".[torch,metrics,bitsandbytes,modelscope]"
2.设置环境变量
export cuda_visible_devices=0 #设置使用gpu
export hf_endpoint=https://hf-mirror.com #设置huggingface的替代地址
export modelscope_cache=/root/autodl-tmp/models/modelscope #设置modelscope中的大模型保存路径
export llamafactory_home=/root/autodl-tmp/llama-factory
3.准备数据
"docker_command_nl": {
"hf_hub_url": "mattcoddity/dockernlcommands"
},
{
"input": "give me a list of containers that have the ubuntu image as their ancestor.",
"instruction": "translate this sentence in docker command",
"output": "docker ps --filter 'ancestor=ubuntu'"
},

]
4.训练大模型
#md model id
model_name_or_path: llm-research/meta-llama-3-8b-instruct
#huggingface model id
#model_name_or_path: meta-llama/meta-llama-3-8b-instruct
### method
stage: sft
do_train: true
finetuning_type: lora
lora_target: all
### dataset
dataset: docker_command_nl
template: llama3
cutoff_len: 1024
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
### output
output_dir: /root/autodl-tmp/my-test/saves/llama3-8b/lora/sft/docker-commnad-nlp/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
### train
per_device_train_batch_size: 4
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
### eval
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500
cd $bin_path/
pwd
cd $llamafactory_home
pwd
llamafactory-cli train $bin_path/conf/llama3_lora_sft_docker_command.yaml
5.合并大模型
#md model id
model_name_or_path: llm-research/meta-llama-3-8b-instruct
#huggingface model id
#model_name_or_path: meta-llama/meta-llama-3-8b-instruct
adapter_name_or_path: /root/autodl-tmp/my-test/saves/llama3-8b/lora/docker-commnad-nlp/sft
template: llama3
export_dir: /root/autodl-tmp/my-test/saves/llama3-8b/lora/docker-commnad-nlp/export
finetuning_type: lora
export_size: 2
export_device: gpu
export_legacy_format: false
cd $bin_path/
pwd
llamafactory-cli export conf/llama3_lora_export_docker_command.yaml
]]>