这里基于whoami示范服务,部署3个实例,分别一一验证各种类型的k8s service服务范畴。
大致逐一从下面列表逐一验证每种类型的service访问方式:
service name- 域名解析结果等
cluster-ipexternal-ip
一些设定如下:
- 测试环境k8s版本号为
v1.27.3 - k8s集群node节点ip地址段范围:
10.0.1.0/24 - k8s集群自动生成pod网段为
10.43.0.0/24 - 本书所列代码皆可拷贝直接粘贴到终端界面直接运行
首先,部署whoami服务
先部署包含3个实例的whoami:
# cat << 'eof' | kubectl apply -f -
apiversion: apps/v1
kind: deployment
metadata:
name: whoami
labels:
app: whoami
spec:
replicas: 3
selector:
matchlabels:
app: whoami
template:
metadata:
labels:
app: whoami
spec:
containers:
- name: whoami
image: containous/whoami
ports:
- containerport: 80
name: web
eof
查看一下:
# kubectl get all
name ready status restarts age
pod/whoami-767d459f67-qffqw 1/1 running 0 23m
pod/whoami-767d459f67-xdv9p 1/1 running 0 23m
pod/whoami-767d459f67-gwpgx 1/1 running 0 23m
name ready up-to-date available age
deployment.apps/whoami 3/3 3 3 23m
name desired current ready age
replicaset.apps/whoami-767d459f67 3 3 3 23m
其次,安装busybox进行调试
安装一个包含有curl的busybox方便后续调试:
kubectl run busybox-curl --image=yauritux/busybox-curl --command -- sleep 3600
另起一个终端,输入下面命令进入:
kubectl exec -ti busybox-curl -n default -- sh
环境准备好之后,下面逐一测试各种类型:
默认cluster ip模式
k8s默认service为cluster ip模式,面向内部pod以及通过ingress对外提供服务。

下面一张图很清晰解释清楚了port和targetport适用情景,port为service对外输出的端口,targetport为服务后端pod的端口,两者之间有一个转换:port -> targetport -> containerport。

创建一个service:
cat << 'eof' | kubectl apply -f -
apiversion: v1
kind: service
metadata:
labels:
name: whoami-clusterip
name: whoami-clusterip
spec:
ports:
- port: 80
targetport: 80
protocol: tcp
selector:
app: whoami
eof
部署后可以查看一下:
name type cluster-ip external-ip port(s) age
service/whoami-clusterip clusterip 10.43.247.74 80/tcp 57s
下面就需要逐一测试了。
域名形式:
# curl whoami-clusterip
hostname: whoami-767d459f67-gwpgx
ip: 127.0.0.1
ip: 10.42.8.35
remoteaddr: 10.42.9.32:35968
get / http/1.1
host: whoami-clusterip
user-agent: curl/7.81.0
accept: */*
cluster ip形式:
# curl 10.43.247.74
hostname: whoami-767d459f67-qffqw
ip: 127.0.0.1
ip: 10.42.3.73
remoteaddr: 10.42.9.32:42398
get / http/1.1
host: 10.43.247.74
user-agent: curl/7.81.0
accept: */*
域名解析,只解析到cluster ip上:
# nslookup whoami-clusterip
server: 10.43.0.10
address: 10.43.0.10:53
name: whoami-clusterip.default.svc.cluster.local
address: 10.43.247.74
external ip模式

原理同cluster ip模式,为指定服务绑定一个额外的一个ip地址。当终端访问该ip地址,将流量一样转发到service。
当访问external ip,其端口转换过程:port -> targetport -> containerport。
与默认service相比,端口转换流程没有增加,但好处对外暴露了一个可访问的ip地址,不过可能需要在交换机/路由器层面提供动静态路由支持。
cat << 'eof' | kubectl apply -f -
apiversion: v1
kind: service
metadata:
labels:
name: whoami-externalip
name: whoami-externalip
spec:
ports:
- port: 80
targetport: 80
protocol: tcp
selector:
app: whoami
externalips:
- 10.10.10.10
eof
服务显示如下,绑定了指定的扩展ip地址10.10.10.10。
# name type cluster-ip external-ip port(s) age
service/whoami-externalip clusterip 10.43.192.118 10.10.10.10 80/tcp 57s
kube-proxy 将在每一个node节点为10.10.10.10上建立一个转发规则,该ip地址的80端口将直接转发到对应的后端三个whoami pod 上。
-a kube-services -d 10.10.10.10/32 -p tcp -m comment --comment "default/whoami-externalip external ip" -m tcp --dport 80 -j kube-ext-qn5hievyupdp6unk
......
-a kube-ext-qn5hievyupdp6unk -j kube-svc-qn5hievyupdp6unk
......
-a kube-svc-qn5hievyupdp6unk ! -s 10.42.0.0/16 -d 10.43.192.118/32 -p tcp -m comment --comment "default/whoami-externalip cluster ip" -m tcp --dport 80 -j kube-mark-masq
-a kube-svc-qn5hievyupdp6unk -m comment --comment "default/whoami-externalip -> 10.42.2.79:80" -m statistic --mode random --probability 0.33333333349 -j kube-sep-jsat6d2kfcsf4ylf
-a kube-svc-qn5hievyupdp6unk -m comment --comment "default/whoami-externalip -> 10.42.3.77:80" -m statistic --mode random --probability 0.50000000000 -j kube-sep-2r66ui3g2ay2imnm
-a kube-svc-qn5hievyupdp6unk -m comment --comment "default/whoami-externalip -> 10.42.8.42:80" -j kube-sep-zhhil2san2g37gcm
访问域名:
# curl whoami-externalip
hostname: whoami-767d459f67-gwpgx
ip: 127.0.0.1
ip: 10.42.8.35
remoteaddr: 10.42.9.32:46746
get / http/1.1
host: whoami-externalip
user-agent: curl/7.81.0
accept: */*
访问clusterip形式:
# curl 10.43.192.118
hostname: whoami-767d459f67-qffqw
ip: 127.0.0.1
ip: 10.42.3.73
remoteaddr: 10.42.9.32:47516
get / http/1.1
host: 10.43.192.118
user-agent: curl/7.81.0
accept: */*
访问暴露的external ip:
# curl 10.10.10.10
hostname: whoami-767d459f67-gwpgx
ip: 127.0.0.1
ip: 10.42.8.35
remoteaddr: 10.42.9.0:38477
get / http/1.1
host: 10.10.10.10
user-agent: curl/7.81.0
accept: */*
域名解析结果只解析到其对应的cluster ip:
# nslookup whoami-externalip
server: 10.43.0.10
address: 10.43.0.10:53
name: whoami-externalip.default.svc.cluster.local
address: 10.43.192.118
nodeport 模式
与cluster ip相比,多了一个nodeport,这个nodeport会在k8s所有node节点上都会开放。
这里有一个端口转换过程:nodeport -> port -> targetport -> containerport,多了一层数据转换过程。

服务定义如下:
cat << 'eof' | kubectl apply -f -
apiversion: v1
kind: service
metadata:
labels:
name: whoami-nodeport
name: whoami-nodeport
spec:
type: nodeport
ports:
- port: 80
targetport: 80
nodeport: 30080
protocol: tcp
selector:
app: whoami
eof
查看一下服务分配地址:
name type cluster-ip external-ip port(s) age
service/whoami-nodeport nodeport 10.43.215.233 80:30080/tcp 57s
访问域名:
# curl whoami-nodeport
hostname: whoami-767d459f67-xdv9p
ip: 127.0.0.1
ip: 10.42.2.75
remoteaddr: 10.42.9.32:36878
get / http/1.1
host: whoami-nodeport
user-agent: curl/7.81.0
accept: */*
测试 cluster ip :
# curl 10.43.215.233
hostname: whoami-767d459f67-qffqw
ip: 127.0.0.1
ip: 10.42.3.73
remoteaddr: 10.42.9.32:40552
get / http/1.1
host: 10.43.215.233
user-agent: curl/7.81.0
accept: */*
因为是在每一个k8s node节点上都会开放一个30080端口,因此可以这样访问 {node ip}:{nodeport},如下node ip地址为10.0.1.11
# curl 10.0.1.11:30080
hostname: whoami-767d459f67-qffqw
ip: 127.0.0.1
ip: 10.42.3.73
remoteaddr: 10.42.1.0:1880
get / http/1.1
host: 10.0.1.11:30080
user-agent: curl/7.81.0
accept: */*
域名还是只解析到对应cluster ip:
# nslookup whoami-nodeport
server: 10.43.0.10
address: 10.43.0.10:53
name: whoami-nodeport.default.svc.cluster.local
address: 10.43.215.233
loadbalancer 模式
loadbalancer模式,会强制k8s service自动开启nodeport。

这里有一张图,详细解析数据流向。
服务数据端口转换过程:port -> nodeport -> port -> targetport -> containerport:
- 与默认
cluster ip相比,多了两层数据转换过程 - 与
nodeport相比,对了一层数据转换过程 - 与
externalip相比,在小流量场景下就没有什么优势了

具体服务定义:
cat << 'eof' | kubectl apply -f -
apiversion: v1
kind: service
metadata:
labels:
name: whoami-clusterip-none
name: whoami-clusterip-none
spec:
clusterip: none
ports:
- port: 80
targetport: 80
protocol: tcp
selector:
app: whoami
eof
查看一下部署结果:
name type cluster-ip external-ip port(s) age
service/whoami-loadbalancer loadbalancer 10.43.63.92 80:30906/tcp 57s
服务域名形式:
# curl whoami-loadbalancer
hostname: whoami-767d459f67-qffqw
ip: 127.0.0.1
ip: 10.42.3.73
remoteaddr: 10.42.9.32:57844
get / http/1.1
host: whoami-loadbalancer
user-agent: curl/7.81.0
accept: */*
测试 cluster-ip
# curl 10.43.63.92
hostname: whoami-767d459f67-xdv9p
ip: 127.0.0.1
ip: 10.42.2.75
remoteaddr: 10.42.9.32:42400
get / http/1.1
host: 10.43.63.92
user-agent: curl/7.81.0
accept: */*
域名解析到cluster ip:
# nslookup whoami-loadbalancer
server: 10.43.0.10
address: 10.43.0.10:53
name: whoami-loadbalancer.default.svc.cluster.local
address: 10.43.63.92
安装loadbalancer
此时whoami-loadbalancer服务对应的external-ip 为 metallb作为负载均衡器。
# kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.13.11/config/manifests/metallb-native.yaml
稍后分配可用的loadbalaner可分配的地址池:
cat << 'eof' | kubectl apply -f -
apiversion: metallb.io/v1beta1
kind: ipaddresspool
metadata:
name: default-pool
namespace: metallb-system
spec:
addresses:
- 10.0.1.100-10.0.1.200
---
apiversion: metallb.io/v1beta1
kind: l2advertisement
metadata:
name: default
namespace: metallb-system
spec:
ipaddresspools:
- default-pool
eof
等安装完成之后,可以看到服务whoami-loadbalancer分配的ip地址为 10.0.1.101 :
name type cluster-ip external-ip port(s) age
......
service/whoami-loadbalancer loadbalancer 10.43.63.92 10.0.1.101 80:30906/tcp 27h
......
测试负载均衡ip地址
测试一下:
# curl 10.0.1.101
hostname: whoami-767d459f67-xdv9p
ip: 127.0.0.1
ip: 10.42.2.78
remoteaddr: 10.42.8.0:33658
get / http/1.1
host: 10.0.1.101
user-agent: curl/7.79.1
accept: */*
我们看到该服务分配的端口为80:30906/tcp,30906为k8s为该服务自动生成的nodeport类型端口。
可以找任一k8s node节点ip地址测试一下:
# curl 10.0.1.12:30906
hostname: whoami-767d459f67-qffqw
ip: 127.0.0.1
ip: 10.42.3.77
remoteaddr: 10.42.2.0:9717
get / http/1.1
host: 10.0.1.12:30906
user-agent: curl/7.81.0
accept: */*
分析一下路由表,可以分析到该负载均衡的external_ip:80的打流量到nodeport:30906上,然后走service对应{pod:80}流量分发逻辑。
-a kube-nodeports -p tcp -m comment --comment "default/whoami-loadbalancer" -m tcp --dport 30906 -j kube-ext-nbtybeexaczi7dpc
......
-a kube-services -d 10.0.1.101/32 -p tcp -m comment --comment "default/whoami-loadbalancer loadbalancer ip" -m tcp --dport 80 -j kube-ext-nbtybeexaczi7dpc
......
-a kube-ext-nbtybeexaczi7dpc -m comment --comment "masquerade traffic for default/whoami-loadbalancer external destinations" -j kube-mark-masq
-a kube-ext-nbtybeexaczi7dpc -j kube-svc-nbtybeexaczi7dpc
......
-a kube-svc-nbtybeexaczi7dpc ! -s 10.42.0.0/16 -d 10.43.63.92/32 -p tcp -m comment --comment "default/whoami-loadbalancer cluster ip" -m tcp --dport 80 -j kube-mark-masq
-a kube-svc-nbtybeexaczi7dpc -m comment --comment "default/whoami-loadbalancer -> 10.42.2.79:80" -m statistic --mode random --probability 0.33333333349 -j kube-sep-e3k3suynfwt2vice
-a kube-svc-nbtybeexaczi7dpc -m comment --comment "default/whoami-loadbalancer -> 10.42.3.77:80" -m statistic --mode random --probability 0.50000000000 -j kube-sep-hg5myvvid7gjoza7
-a kube-svc-nbtybeexaczi7dpc -m comment --comment "default/whoami-loadbalancer -> 10.42.8.42:80" -j kube-sep-gfjh72ycbkbfb6og
headless 无头模式
一般应用在有状态的服务,或需要终端调用者自己实现负载均衡,等一些特定场景。
通过调用者从端口角度分析,数据转换流程:targetport -> containerport。
在意服务性能的场景,不妨试试无头模式。

服务定义:
cat << 'eof' | kubectl apply -f -
apiversion: v1
kind: service
metadata:
labels:
name: whoami-clusterip-none
name: whoami-clusterip-none
spec:
clusterip: none
ports:
- port: 80
targetport: 80
protocol: tcp
selector:
app: whoami
eof
查看服务部署情况:
name type cluster-ip external-ip port(s) age
service/whoami-clusterip-none clusterip none 80/tcp 9h
通过service域名访问,k8s会自动根据服务域名whoami-clusterip-none进行pick后端对应pod ip地址。
# curl whoami-clusterip-none
hostname: whoami-767d459f67-xdv9p
ip: 127.0.0.1
ip: 10.42.2.75
remoteaddr: 10.42.9.32:34998
get / http/1.1
host: whoami-clusterip-none
user-agent: curl/7.81.0
accept: */*
查询dns会把所有节点都列出来。
# nslookup whoami-clusterip-none
server: 10.43.0.10
address: 10.43.0.10:53
name: whoami-clusterip-none.default.svc.cluster.local
address: 10.42.3.73
name: whoami-clusterip-none.default.svc.cluster.local
address: 10.42.2.75
name: whoami-clusterip-none.default.svc.cluster.local
address: 10.42.8.35
external name模式
用于引进带域名的外部服务,这里引入内部服务作为测试。
多了一层域名解析过程,端口转换流程依赖于所引入服务的服务设定。

服务定义:
cat << 'eof' | kubectl apply -f -
apiversion: v1
kind: service
metadata:
labels:
name: whoami-externalname
name: whoami-externalname
spec:
type: externalname
externalname: whoami-clusterip.default.svc.cluster.local
eof
这里外联的是whoami-clusterip服务的完整访问域名。
查看服务部署情况:
name type cluster-ip external-ip port(s) age
service/whoami-externalname externalname whoami-clusterip.default 9h
根据域名访问测试:
# curl whoami-externalname
hostname: whoami-767d459f67-qffqw
ip: 127.0.0.1
ip: 10.42.3.77
remoteaddr: 10.42.9.35:36756
get / http/1.1
host: whoami-externalname
user-agent: curl/7.81.0
accept: */*
dns解析结果:
# nslookup whoami-externalname
server: 10.43.0.10
address: 10.43.0.10:53
whoami-externalname.default.svc.cluster.local canonical name = whoami-clusterip.default.svc.cluster.local
name: whoami-clusterip.default.svc.cluster.local
address: 10.43.247.74
小结
简要分析了各种类型service定义、服务引用场景以及测试流程等,整理清楚了,也方便在具体业务场景中进行抉择选择具体服务类型。
]]>
nfs,这里记录一下操作记录。
列出当前storageclass:
kubectl get sc
name provisioner reclaimpolicy volumebindingmode allowvolumeexpansion age
local-path (default) rancher.io/local-path delete waitforfirstconsumer false 17d
nfs cluster.local/nfs-nfs-subdir-external-provisioner delete immediate true 6d14h
首先,将默认的名称为local-path修改为false:
kubectl patch storageclass local-path -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"false"}}}'
然后,将nfs设置为默认:
kubectl patch storageclass nfs -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
操作完成之后,校验一下,可以看到已经成功将nfs设置为默认的storageclass选项。
kubectl get sc
name provisioner reclaimpolicy volumebindingmode allowvolumeexpansion age
local-path rancher.io/local-path delete waitforfirstconsumer false 17d
nfs (default) cluster.local/nfs-nfs-subdir-external-provisioner delete immediate true 6d14h
ref:
]]>
参与开源不是为了证明什么,而是为了更好的配合工作。开源和工作在绝大部分时间,都是可以和谐共处,互相促进,win-win双赢。
本文内容记录了为 项目提交的一次pull request提交 (访问地址: )完整过程,提交内容为一个独立的服务发现模块,本文目的是为团队的其他同学参与社区项目分享的行为提供一个简单可遵循、可操作模型。
概括来讲,简要操作流程如下:
- 首先,确定需要开源的部分
- 其次,在项目社区中分享我们的看法和后续行为等
- 然后,准备提交内容
- 接着,提交pull request,接受社区审核,反复调整修改
- 后续,关注社区的走向,持续改进
下面为每一步具体操作的流水账。
提前预警,图多费流量,慎入 :))
首先,我们有一个consul kv服务发现组件
作为nginx用户,我们实际场景使用 模块,结合consul kv作为服务注册和发现形式。
我们基于apisix构建http api服务网关,没有发现现成的consul kv形式服务发现模块,既然实际业务需要,我们需要把它按照接口规范开发出来,以适应我们自己的实际场景。
当服务发现模块功能开发出来后,也是仅仅能满足基本需求,还不够完善,但这时改进的思路并不是非常清楚,
既然开源社区也有类似的需求,那我们可以考虑分享开源出去,接收整个社区的考验,大家一起改进。
限于日常思维角度的局限,若是仅仅满足工作需要,那么开源出去会让你的代码接受到社区方方面面的审核,尤其是针对代码风格、功能、执行等有严格要求的apisix项目。摆正心态,接受代码评审并调整,最终结果无疑是让代码更加健壮,好事一桩嘛。
当然开源出去之后,该模块的变更以及优化等行为就完全归属整个社区了,群策群力,是一种比较期待的演进方式。
第一步,咨询社区意见
一个优秀的开源项目,为了稳定健康发展,一般会提供邮件组方便社区参与者咨询、沟通协调等。
一般来说,github会提供issues列表方便项目使用者提交bug,若我们想在社区中表达意图、观点等,就不如发在社区邮件组中,这样能够得到更多的关注。比如,我们想给社区共享一个完整的服务发现模块,就可以直接在邮件组中描述大致功能,以及大致处理流程等,让社区知道我们的真实意图。
apisix开发邮件组地址为:dev@apisix.apache.org,但一般的邮件组都需要注意如下事项:
- 沟通需要使用英文
- 这也是apisix项目国际化需求
- 虽然你也知道阅读邮件的有几个中国的糙老爷们,但也会有来自其他国家的用户
- 当然在github上所有的项目沟通都需要使用英文,这是一个良好的开源社区沟通习惯
- 推荐一个微软英语在线协作辅助工具: ,可以帮助校验语法错误等
- 无法传递富文本
- 使用纯文本即可
- 类似我有格式化强迫症患者,直接粘贴 markdown 格式文本
无法传递图片
- 直接传递图片url地址
- 若需要传递图片,提供一个小技巧:新建一个issues表单,直接拖拽图片到表单处,然后获得图片地址即可,无须提交
issues表单

上传图片
下面是我发送的邮件截图:

因为apache邮件组不支持富文本和图片,实际看到的效果就没有那么好看了,下面的连接包含了该讨论完整的回复内容:
不方便打开的话,下面提供完整邮件讨论截图,很长的截图,呵呵:

总之,断断续续经过三周时间的讨论,这个过程需要有些耐心。发完邮件等有了积极反馈,下面就可以着手准备提交代码了。
第二步,准备提交
fork到自己仓库
去 fork到自己仓库中,然后克隆到自己工作机来。
注意,需要时刻保持和主干保持一致:
git remote add upstream https://github.com/apache/apisix.git
下面就是动手开干了。
按需调整代码
consul kv服务发现模块文件是 consul_kv.lua,相对位置为:apisix/discovery/consul_kv.lua。我们想提交到项目主干,那么代码就必须遵循已有规范。
针对apisix的服务发现代码,需要有配置项,就必须给出一套完整的服务配置 schema 定义,如下。
local schema = {
type = "object",
properties = {
servers = {
type = "array",
minitems = 1,
items = {
type = "string",
}
},
fetch_interval = {type = "integer", minimum = 1, default = 3},
keepalive = {
type = "boolean",
default = true
},
prefix = {type = "string", default = "upstreams"},
weight = {type = "integer", minimum = 1, default = 1},
timeout = {
type = "object",
properties = {
connect = {type = "integer", minimum = 1, default = 2000},
read = {type = "integer", minimum = 1, default = 2000},
wait = {type = "integer", minimum = 1, default = 60}
},
default = {
connect = 2000,
read = 2000,
wait = 60,
}
},
skip_keys = {
type = "array",
minitems = 1,
items = {
type = "string",
}
},
default_service = {
type = "object",
properties = {
host = {type = "string"},
port = {type = "integer"},
metadata = {
type = "object",
properties = {
fail_timeout = {type = "integer", default = 1},
weigth = {type = "integer", default = 1},
max_fails = {type = "integer", default = 1}
},
default = {
fail_timeout = 1,
weigth = 1,
max_fails = 1
}
}
}
}
},
required = {"servers"}
}
当然,你需要区分每一个配置项是不是必填项,非必传项需要具有默认值,以及上限或下限约束等。
下面需要在该模块启动时进行检测用户配置是否错误,无法兼容、恢复错误的话,需要直接使用lua内置错误日志接口输出:
error("errr msg")
另外,若要引入 resty.worker.events 组件,不要提前require,比如在文件头部提前声明时:
loca events = require("resty.worker.events")
启动后,就有可能在日志文件中出现如下异常:
2021/02/23 02:32:20 [error] 7#7: init_worker_by_lua error: /usr/local/share/lua/5.1/resty/worker/events.lua:175: attempt to index local 'handler_list' (a nil value)
stack traceback:
/usr/local/share/lua/5.1/resty/worker/events.lua:175: in function 'do_handlerlist'
/usr/local/share/lua/5.1/resty/worker/events.lua:215: in function 'do_event_json'
/usr/local/share/lua/5.1/resty/worker/events.lua:361: in function 'post'
/usr/local/share/lua/5.1/resty/worker/events.lua:614: in function 'configure'
/usr/local/apisix/apisix/init.lua:94: in function 'http_init_worker'
init_worker_by_lua:5: in main chunk
推荐做法是延迟加载,在该模块被加载时进行引用。
local events
local events_list
......
function _m.init_worker()
......
events = require("resty.worker.events")
events_list = events.event_list(
"discovery_consul_update_application",
"updating"
)
if 0 ~= ngx.worker.id() then
events.register(discovery_consul_callback, events_list._source, events_list.updating)
return
end
......
end
单元测试依赖
单元测试代码的执行,会在你提交pr代码后自动执行持续集成行为内执行。
首先,需要本机执行单元测试前,需要提前准备好所需docker测试实例:
docker run --rm --name consul_1 -d -p 8500:8500 consul:1.7 consul agent -server -bootstrap-expect=1 -client 0.0.0.0 -log-level info -data-dir=/consul/data
docker run --rm --name consul_2 -d -p 8600:8500 consul:1.7 consul agent -server -bootstrap-expect=1 -client 0.0.0.0 -log-level info -data-dir=/consul/data
docker run --rm -d \
-e etcd_enable_v2=true \
-e allow_none_authentication=yes \
-e etcd_advertise_client_urls=http://0.0.0.0:2379 \
-e etcd_listen_client_urls=http://0.0.0.0:2379 \
-p 2379:2379 \
registry.api.weibo.com/wesync/wbgw/etcd:3.4.9
然后,安装项目依赖:
make deps
其次,别忘记在apisix项目持续集成脚本相应位置添加相应依赖。
比如,因为单元测试依赖于端口分别为7500和7600的两个consul server实例,需要在执行单元测试之前提前运行,因此你需要在对应的持续集成文件上添加所需运行实例。比如其中一个位置:

无测试不编码
仅仅提供服务发现consul_kv.lua这一个文件,是无法被仓库管理员采纳的,因为除了你自己以外,别人无法确定你提交的代码所提供功能是否足够让人信服,除非你能提供较为完整的 test::nginx 单元测试支持,自我证明。
test::nginx 单元测试可能针对很多人来讲,是一个拦路虎,但其实有些耐心,你会发现它的美妙之处。
简单入门可参考 (若只需要学习单元测试,其实不需要购买整个专辑的)。在使用过程中需要参考在线文档: ,需要一些耐心花费一点时间慢慢消化。
如何运行nginx单元测试案例,具体参看:
至于apisix定制部分单元测试部分,可以直接参考已有的单元测试文件即可。
consul kv服务发现的单元测试模块相对路径 t/discovery/consul_kv.lua,在线地址为: 。该文件大约500多行,比真正的模块consul_kv.lua代码行数还多。但比较完整覆盖了所能想到的所有场景,虽然写起来虽然有些麻烦,但针对应用到线上大量业务的核心代码,无论多认真和谨慎都是不为过的。
以往针对关键核心模块的每一次迭代,心里面大概有些忐忑七上八下吧,也不太敢直接应用到线上。现在有了单元测试各种场景的覆盖辅助验证迭代变更效果,自信心是有了,也可以给别人拍着胸脯保证修改没问题。当然若后续发现隐藏的问题,直接添加上对应的单元测试覆盖上即可。
我们这次只提供一个服务发现模块,因此只需要单独测试consul_kv.t文件即可:
# prove -itest-nginx/lib -i./ t/discovery/consul_kv.t
......
t/discovery/consul_kv.t .. ok
all tests successful.
files=1, tests=102, 36 wallclock secs ( 0.05 usr 0.01 sys 0.78 cusr 0.41 csys = 1.25 cpu)
result: pass
出现测试案例失败问题,可以去 apisix/t/servroot/logs 路径下查看 error.log 文件暴露出的异常等问题。
有些一些测试用例需要组合一组较为复杂的使用场景,比如我们准备一组后端节点:
- 127.0.0.1:30511,输出
server 1 - 127.0.0.1:30512,输出
server 2 - 127.0.0.1:30513,输出
server 3 - 127.0.0.1:30514,输出
server 4
这些节点将被频繁执行注册consul节点然后再解除注册若干循环过程:清理注册 -> 注册 -> 解除注册 -> 注册 -> 解除注册 -> 注册 -> 解除注册 -> 注册 ,目的检验已解除注册的失效节点是否还会存在内存中等。
有些操作,比如注册或解除注册节点这些操作,网关的consul_kv.lua服务模块在物理层面需要wait一点时间等待网关消化这些变化,因此我们需要额外提供一个 /sleep 接口,请求时需要故意休眠几秒钟时间等待下一次请求生效。
=== test 7: test register & unregister nodes
--- yaml_config eval: $::yaml_config
--- apisix_yaml
routes:
-
uri: /*
upstream:
service_name: http://127.0.0.1:8500/v1/kv/upstreams/webpages/
discovery_type: consul_kv
type: roundrobin
#end
--- config
location /v1/kv {
proxy_pass http://127.0.0.1:8500;
}
location /sleep {
content_by_lua_block {
local args = ngx.req.get_uri_args()
local sec = args.sec or "2"
ngx.sleep(tonumber(sec))
ngx.say("ok")
}
}
--- timeout: 6
--- request eval
[
"delete /v1/kv/upstreams/webpages/?recurse=true",
"put /v1/kv/upstreams/webpages/127.0.0.1:30511\n" . "{\"weight\": 1, \"max_fails\": 2, \"fail_timeout\": 1}",
"get /sleep?sec=5",
"get /hello",
"put /v1/kv/upstreams/webpages/127.0.0.1:30512\n" . "{\"weight\": 1, \"max_fails\": 2, \"fail_timeout\": 1}",
"get /sleep",
"get /hello",
"get /hello",
"delete /v1/kv/upstreams/webpages/127.0.0.1:30511",
"delete /v1/kv/upstreams/webpages/127.0.0.1:30512",
"put /v1/kv/upstreams/webpages/127.0.0.1:30513\n" . "{\"weight\": 1, \"max_fails\": 2, \"fail_timeout\": 1}",
"put /v1/kv/upstreams/webpages/127.0.0.1:30514\n" . "{\"weight\": 1, \"max_fails\": 2, \"fail_timeout\": 1}",
"get /sleep",
"get /hello?random1",
"get /hello?random2",
"get /hello?random3",
"get /hello?random4",
"delete /v1/kv/upstreams/webpages/127.0.0.1:30513",
"delete /v1/kv/upstreams/webpages/127.0.0.1:30514",
"put /v1/kv/upstreams/webpages/127.0.0.1:30511\n" . "{\"weight\": 1, \"max_fails\": 2, \"fail_timeout\": 1}",
"put /v1/kv/upstreams/webpages/127.0.0.1:30512\n" . "{\"weight\": 1, \"max_fails\": 2, \"fail_timeout\": 1}",
"get /sleep?sec=5",
"get /hello?random1",
"get /hello?random2",
"get /hello?random3",
"get /hello?random4",
]
--- response_body_like eval
[
qr/true/,
qr/true/,
qr/ok\n/,
qr/server 1\n/,
qr/true/,
qr/ok\n/,
qr/server [1-2]\n/,
qr/server [1-2]\n/,
qr/true/,
qr/true/,
qr/true/,
qr/true/,
qr/ok\n/,
qr/server [3-4]\n/,
qr/server [3-4]\n/,
qr/server [3-4]\n/,
qr/server [3-4]\n/,
qr/true/,
qr/true/,
qr/true/,
qr/true/,
qr/ok\n/,
qr/server [1-2]\n/,
qr/server [1-2]\n/,
qr/server [1-2]\n/,
qr/server [1-2]\n/
]
准备文档
除了代码能够正常运转,我们还需要准备相应的markdown文档辅助说明如何使用我们的模块,帮助社区用户更好使用它。
社区一般以英文文档为先, 只有在精力满足的情况下,可以补充中文文档。
下面就是要准备markdown文档了,其文档路径为:doc/discovery/consul_kv.md,单独的文档需要在其它已有文档挂接上对应链接,方便索引。
文档路径为:doc/discovery/consul_kv.md,在线地址:
一般建议需要在文档中能够清楚说明模块的使用方式,以及注意事项,尤其是配置参数使用方式等。比如下面的配置项说明:
```yaml
discovery:
consul_kv:
servers:
- "http://127.0.0.1:8500"
- "http://127.0.0.1:8600"
prefix: "upstreams"
skip_keys: # if you need to skip special keys
- "upstreams/unused_api/"
timeout:
connect: 1000 # default 2000 ms
read: 1000 # default 2000 ms
wait: 60 # default 60 sec
weight: 1 # default 1
fetch_interval: 5 # default 3 sec, only take effect for keepalive: false way
keepalive: true # default true, use the long pull way to query consul servers
default_server: # you can define default server when missing hit
host: "127.0.0.1"
port: 20999
metadata:
fail_timeout: 1 # default 1 ms
weight: 1 # default 1
max_fails: 1 # default 1
```
......
the `keepalive` has two optional values:
- `true`, default and recommend value, use the long pull way to query consul servers
- `false`, not recommend, it would use the short pull way to query consul servers, then you can set the `fetch_interval` for fetch interval
每一个文档都不应该成为信息孤岛,它需要在其它文档上挂载上一个连接地址,因此我们需要在合适的地方,比如需要在 doc/discovery.md最下面添加链接地址描述:
## discovery modules
- eureka
- [consul kv](discovery/consul_kv.md)
模块代码,测试文件,以及文档等准备好了之后,下面就是准备提交代码到自己仓库。
验证提交语法规范
所有内容准备好之后,建议执行 make lint 和 make license-check 两个命令检测代码、markdown文档等是否满足项目规范要求。
# make lint
./utils/check-lua-code-style.sh
luacheck -q apisix t/lib
total: 0 warnings / 0 errors in 133 files
find apisix -name '*.lua' '!' -wholename apisix/cli/ngx_tpl.lua -exec ./utils/lj-releng '{}'
grep -e 'error.*.lua:' /tmp/check.log
true
'[' -s /tmp/error.log ']'
./utils/check-test-code-style.sh
find t -name '*.t' -exec grep -e '\-\-\-\s (skip|only|last)$' '{}'
true
'[' -s /tmp/error.log ']'
find t -name '*.t' -exec ./utils/reindex '{}'
grep done. /tmp/check.log
true
'[' -s /tmp/error.log ']'
# make license-check
.travis/openwhisk-utilities/scancode/scancode.py --config .travis/asf-release.cfg ./
reading configuration file [.travis/asf-release.cfg]...
scanning files starting at [./]...
all checks passed.
若检查出语法方面问题,认真调整,直到找不到问题所在。
这次pr提交之前,忘记这回事了,会导致多了若干次次submit提交。
第三步,提交pull request
去凯发k8网页登录官网: 新建一个new pull request,后面将使用pr指代pull request。
pr标题格式
pr提交标题是规范要求的,模板如下:
{type}: {desc}
其中{type}指代本次pr类型,具体值如下,尽量不要搞错:
feat:新功能(feature)fix:修补bugdocs:文档(documentation)style: 格式(不影响代码运行的变动)refactor:重构(即不是新增功能,也不是修改bug的代码变动)test:增加测试chore:构建过程或辅助工具的变动- ……
其中{desc}需要概括本次提交内容。
比如这次标题为:feat: add consul kv discovery module。
填充pr内容
pr内容模板化,为标准的github markdown格式,主要目的说明本次提交内容,示范如下:
### what this pr does / why we need it:
### pre-submission checklist:
* [ ] did you explain what problem does this pr solve? or what new features have been added?
* [ ] have you added corresponding test cases?
* [ ] have you modified the corresponding document?
* [ ] is this pr backward compatible? **if it is not backward compatible, please discuss on the [mailing list](https://github.com/apache/apisix/tree/master#community) first**
按照模板格式填写,省心省力,如下:
### what this pr does / why we need it:
as i mentioned previously in the mail-list, my team submit our `consul_kv` discovery module now.
more introductions here:
https://github.com/yongboy/apisix/blob/consul_kv/doc/discovery/consul_kv.md
### pre-submission checklist:
* [x] did you explain what problem does this pr solve? or what new features have been added?
* [x] have you added corresponding test cases?
* [x] have you modified the corresponding document?
* [x] is this pr backward compatible? **if it is not backward compatible, please discuss on the [mailing list](https://github.com/apache/apisix/tree/master#community) first**
认真接受评审和建议
提交pr之后,才是一个开始,起点。
apisix项目会自动针对我们所提交内容执行持续集成,apisix项目的检查项很多,比如针对markdown格式就很严格:

持续集成不通过,按照要求微调吧,也是标准化的要求。
我们在push代码之前,使用 make lint 和 make license-check 两个命令提前检测还是十分有必要的,提前检测语法等。
首先,一定要确保持续集成不能出错。持续集成通不过,说明我们的准备还不充分,继续调整修改,继续提交,一直到持续集成完全执行成功为止。
保证持续集成执行成功,这是最基本的要求,否则社区无法确认我们的代码是否基本合格。
放松心态,准备开始改进bug,以及接受社区的各种代码评审和改进意见吧。
其次,就是要虚心接受社区代码评审和改进意见了,这是最关键的一步。
下面是一些建议:
- 真正代码bug,认真修改

- 逻辑处理不合理的地方,思考并给出一些处理思路,确定好之后开始调整即可

- 有些提议可能会超出本次提交范围,说明原因,给出拒绝理由,可以婉拒嘛,比如可以放在下一次的提交中。

- 若有遇到自己处理不了的问题,积极向社区寻求帮助吧。
- 针对一批次修改再次提交后,会再次执行持续集成,一样确保持续集成不能够失败,然后继续等待下一轮的审核
认真对待每一个建议,有则改之无则加勉,不知不觉之间就进步了很多,代码质量也得到了提升。
经过多次的微调,凯发k8网页登录的服务发现核心模块基本上已趋于完善了一版,这已经和还没准备分享出来之前的原始文件相比已经天差地别了 :))
下面是本次pr包含的多次提交、代码评审以及答复等完整流程截图:

被合并到主分支之后,有没有感觉到整个社区都在帮助我们一起改进,快不快哉 ?
关于依赖项的处理
本次提交的服务发现模块依赖一个组件:lua-resty-consul,其仓库地址:
但apisix项目针对项目依赖,采用的 luarocks 管理,在 2021-2-20 之前该组件托管在 上面最新版本为 0.2-0,这就很难办了。
我的处理步骤如下:
- 首先我在github上面向作者提交一个求助: 然而并没有在一两周时间内没有等到作者回复
- 无奈,只好自己在 luarocks 单独提交一个暂时性的凯发天生赢家一触即发官网的解决方案:
- 三周左右,终于等到该组件作者提交最新版到 luarocks 站点,既然官方更新了,那就把服务发现模块里面的依赖修改为官方最新地址吧,再次提价一个pr:
有些一波三折 :))

第四步,关于后续
一旦合并到主分支后,后续的演进整个社区都可以参与进来,可能有人提 issue,可能有人提 pr 修改等,后续我们想为该模块继续提交,那将是另外一个pr的事情。
我们可以继续做以下事情:
- 根据实际需要重构
- 若有人提issue是,自然是fixbug;实践中遇到的bug,修复它
- 需要添加新的单元测试覆盖到新的特性
- 若有需要,就需要添加新的文档进行描述
毫无疑问,这是一个良性循环。
小结
参与社区开发的其它类型提交,可能会比上面所述简单很多,但大都可以看做是以上行为的一个子集。
参与开源,也会为我们打开一扇窗户,去除自身的狭隘。积极向社区靠拢,这需要磨去一些思维或认知的棱角,虚心认识到自我的不足,并不断调整不断进步。
加油!
]]>
线上运行的 apisix 为 1.5 版本,而社区已经发布了 apisix 2.2,是时候需要升级到最新版了,能够享受最版本带来的大量的bugfix,性能增强,以及新增特性的支持等~
从apisix 1.5升级到apisix 2.2过程中,不是一帆风顺的,中间踩了不少坑,所谓前车之鉴后事之师,这里给大家简单梳理一下我们团队所在具体业务环境下,升级过程中踩的若干坑,以及一些需要避免的若干注意事项等。
下文所说原先版本,皆指apisix 1.5,新版则是apisix 2.2版本。
一、已有服务发现机制无法正常工作
针对上游upstream没有使用服务发现的路由来讲,本次升级没有遇到什么问题。
公司内部线上业务大都基于consul kv方式实现服务注册和服务发现,因此我们自行实现了一个 consul_kv.lua 模块实现服务发现流程。
这在apisix 1.5下面一切工作正常。
但在apisix 2.2下面,就无法直接工作了,原因如下:
- 服务发现配置指令变了
- 上游对象包含服务发现时需增加字段
discovery_type进行索引
2.1 服务发现配置指令变了
原先运行中仅支持一种服务发现机制,需要配置在 apisix层级下面:
apisix:
......
discover: consul_kv
......
新版需要直接在config*.yaml文件中顶层层级下进行配置,可支持多种不同的路由发现机制,如下:
discovery: # service discovery center
eureka:
host: # it's possible to define multiple eureka hosts addresses of the same eureka cluster.
- "http://127.0.0.1:8761"
prefix: "/eureka/"
fetch_interval: 30 # default 30s
weight: 100 # default weight for node
timeout:
connect: 2000 # default 2000ms
send: 2000 # default 2000ms
read: 5000
我们有所变通,直接在配置文件顶层配置consul_kv多个集群相关参数,避免 discovery 层级过深。
discovery:
consul_kv: 1
consul_kv:
servers:
-
host: "172.19.5.30"
port: 8500
-
host: "172.19.5.31"
port: 8500
prefix: "upstreams"
timeout:
connect: 6000
read: 6000
wait: 60
weight: 1
delay: 5
connect_type: "long" # long connect
......
当然,这仅仅保证了服务发现模块能够在启动时被正常加载。
推荐阅读:
2.2 upstream对象新增字段discovery_type
apisix当前同时支持多种服务发现机制,这个很赞。对应的代价,就是需要额外引入 discovery_type 字段,用于索引可能同时存在的多个服务发现机制。
以 cousul kv方式服务发现为例,那么需要在已有的 upstream 对象中需要添加该字段:
"discovery_type" : "consul_kv"
原先的一个upstream对象,仅仅需要 service_name 字段属性指定服务发现相关地址即可:
{
"id": "d6c1d325-9003-4217-808d-249aaf52168e",
"name": "grpc_upstream_hello",
......
"service_name": "http://172.19.5.30:8500/v1/kv/upstreams/grpc/grpc_hello",
"create_time": 1610437522,
"desc": "demo grpc service",
"type": "roundrobin"
}
而新版的则需要添加discovery_type字段,表明该service_name 字段对应的具体模块名称,效果如下:
{
"id": "d6c1d325-9003-4217-808d-249aaf52168e",
"name": "grpc_upstream_hello",
......
"service_name": "http://172.19.5.30:8500/v1/kv/upstreams/grpc/grpc_hello",
"create_time": 1610437522,
"desc": "demo grpc service",
"type": "roundrobin",
"discovery_type":"consul_kv"
}
后面我们若支持consul service或etcd kv方式服务发现机制,则会非常弹性和清晰。
调整了配置指令,添加上述字段之后,后端服务发现其实就已经起作用了。
但grpc代理路由并不会生效……
二、grpc当前不支持upstream_id
在我们的系统中,上游和路由是需要单独分开管理的,因此创建的http或grpc路由需要处理支持upstream_id的索引。
这在1.5版本中,grpc路由是没问题的,但到了apisix 2.2版本中,维护者 @spacewander 暂时没做支持,原因是规划grpc路由和dubbo路由处理逻辑趋于一致,更为紧凑。从维护角度我是认可的,但作为使用者来讲,这就有些不合理了,直接丢弃了针对以往数据的支持。
作为当前geek一些方式,在 apisix/init.lua 中,最小成本 (优雅和成本成反比)修改如下,找到如下代码:
-- todo: support upstream id
api_ctx.matched_upstream = (route.dns_value and
route.dns_value.upstream)
or route.value.upstream
直接替换为下面代码即可解决燃眉之急:
local up_id = route.value.upstream_id
if up_id then
local upstreams = core.config.fetch_created_obj("/upstreams")
if upstreams then
local upstream = upstreams:get(tostring(up_id))
if not upstream then
core.log.error("failed to find upstream by id: " .. up_id)
return core.response.exit(502)
end
if upstream.has_domain then
local err
upstream, err = lru_resolved_domain(upstream,
upstream.modifiedindex,
parse_domain_in_up,
upstream)
if err then
core.log.error("failed to get resolved upstream: ", err)
return core.response.exit(500)
end
end
if upstream.value.pass_host then
api_ctx.pass_host = upstream.value.pass_host
api_ctx.upstream_host = upstream.value.upstream_host
end
core.log.info("parsed upstream: ", core.json.delay_encode(upstream))
api_ctx.matched_upstream = upstream.dns_value or upstream.value
end
else
api_ctx.matched_upstream = (route.dns_value and
route.dns_value.upstream)
or route.value.upstream
end
三、自定义auth插件需要微调
新版的apisix auth授权插件支持多个授权插件串行执行,这个功能也很赞,但此举导致了先前为具体业务定制的授权插件无法正常工作,这时需要微调一下。
原先调用方式:
local consumers = core.lrucache.plugin(plugin_name, "consumers_key",
consumer_conf.conf_version,
create_consume_cache, consumer_conf)
因为新版的lrucache不再提供 plugin 函数,需要微调一下:
local lrucache = core.lrucache.new({
type = "plugin",
})
......
local consumers = lrucache("consumers_key", consumer_conf.conf_version,
create_consume_cache, consumer_conf)
另一处是,顺利授权之后,需要赋值consumer相关信息:
ctx.consumer = consumer
ctx.consumer_id = consumer.consumer_id
此时需要替换成如下方式,为(可能存在的)后续的授权插件继续作用。
consumer_mod.attach_consumer(ctx, consumer, consumer_conf)
更多请参考:apisix/plugins/key-auth.lua 源码。
四、etcd v2数据迁移到v3
迁移分为三步:
- 升级线上已有etcd 3.3.*版本到3.4.*,满足新版apisix的要求,这时etcd实例同时支持了v2和v3格式数据
- 迁移v2数据到v3
- 因为数据量不是非常多,我采取了一个非常简单和原始的方式
- 使用 etcdctl 完成v2数据到导出
- 然后使用文本编辑器vim等完成数据的替换,生成etcdctl v3格式的数据导入命令脚本
- 运行之后v3数据导入脚本,完成v2到v3的数据导入
- 修改v3
/apisix/upstreams中包含服务注册的数据,一一添加"discovery_type" : "consul_kv"属性
基于以上操作之后,从而完成了etcd v2到v3的数据迁移。
五、启动apisix后发现etcd v3已有数据无法加载
我们在运维层面,使用 /usr/local/openresty/bin/openresty -p /usr/local/apisix -g daemon off; 方式运行网关程序。
这也就导致,自动忽略了官方提倡的:apisix start 命令自动提前为etcd v3初始化的一些键值对内容。
因此,需要提前为etcd v3建立以下键值对内容:
key value
/apisix/routes : init_dir
/apisix/upstreams : init_dir
/apisix/services : init_dir
/apisix/plugins : init_dir
/apisix/consumers : init_dir
/apisix/node_status : init_dir
/apisix/ssl : init_dir
/apisix/global_rules : init_dir
/apisix/stream_routes : init_dir
/apisix/proto : init_dir
/apisix/plugin_metadata : init_dir
不提前建立的话,就会导致apisix重启后,无法正常加载etcd中已有数据。
其实有一个补救措施,需要修改 apisix/init.lua 内容,找到如下代码:
if not dir_res.nodes then
dir_res.nodes = {}
end
比较geek的行为,使用下面代码替换一下即可完成兼容:
if dir_res.key then
dir_res.nodes = { clone_tab(dir_res) }
else
dir_res.nodes = {}
end
六、apisix-dashboard的支持
我们基于apisix-dashboard定制开发了大量的针对公司实际业务非常实用的企业级特性,但也导致了无法直接升级到最新版的apisix-dashboard。
因为非常基础的上游和路由没有发生多大改变,因此这部分升级的需求可以忽略。
实际上,只是在提交上游表单时,包含服务注册信息json字符串中需要增加 discovery_type 字段和对应值即可完成支持。
七、小结
花费了一些时间完成了从apisix 1.5升级到apisix 2.2的行为,虽然有些坑,但整体来讲,还算顺利。目前已经上线并全量部署运行,目前运行良好。
针对还停留在apisix 1.5的用户,新版增加了control api以及多种服务发现等新特性支持,还是非常值得升级的。
升级之前,不妨仔细阅读每一个版本的升级日志(地址: ),然后需要根据具体业务做好兼容测试准备和准备升级步骤,这些都是非常有必要的。
针对我们团队来讲,升级到最新版,一方面降低了版本升级的压力,另一方面也能够辅助我们能参与到开源社区中去,挺好~
]]>
最近一段时间,要为一个手机终端app程序从零开始设计一整套http api,因为面向的用户很固定,一个新的移动端app。目前还是项目初期,自然要求一切快速、从简,实用性为主。
下面将逐一论述我们是如何设计http api,虽然相对大部分人而言,没有什么新意,但对我来说很新鲜的。避免忘却,趁着空闲尽快记录下来。
技术堆栈的选择
php嘛?团队内也没几个人熟悉。
java?好几年没有碰过了,那么复杂的凯发天生赢家一触即发官网的解决方案,再加上团队内也没什么人会 ……
团队使用过lua,基于openresty构建过tcp、http网关等,对lua nginx组合非常熟悉,能够快速的应用在线上环境。再说lua语法小巧、简单,一个新手半天就可以基本熟悉,马上开工。
看来,nginx lua是目前最为适合我们的了。
http api,需要充分利用http具体操作语义,来应对具体的业务操作方法。基于此,没有闭门造车,我们选择了 这么一个小巧的框架,用于辅助http api的开发开发。
嗯,openresty lua lor,就构成了我们简单技术堆栈。
http api简要设计
http api路径和语义
每一具体业务逻辑,直接在url path中体现出来。我们要的是简单快速,数据结构之间的连接关系,尽可能的去淡化。eg:
/resource/video/id
比如用户反馈这一模块,将使用下面比较固定的路径:
/user/feedback
get,以用户维度查询反馈的历史列表,可分页curl -x get http://localhost/user/feedback?page=1
post,提交一个反馈curl -x post http://localhost/user/feedback -d "content=hello"
delete,删除一个或多个反馈,参数附加在url路径中。curl -x delete http://localhost/user/feedback?id=1001
put,更新评论内容curl -x put http://localhost/user/feedback/1234 -d "content=hello2"
用户属性很多,用户昵称只是其中一个部分,因此更新昵称这一行为,http的 patch 方法可更精准的描述部分数据更新的业务需求:
/user/nickname
patch,更新用户昵称,昵称是用户属性之一,可以使用更轻量级的patch语义curl -x patch http://localhost/user/nickname -d "nickname=hello2"
嗯,同一类的资源url虽然固定了,但http method呈现了不同的业务逻辑需求。
http api的访问授权
实际业务http api的访问是需要授权的。
传统的access token凯发天生赢家一触即发官网的解决方案,有session回话机制,一般需要结合web浏览器,需要写入到cookie中,或生产一个jsessionid用于标识等。这针对单纯面向移动终端的http api后端来讲,并没有义务去做这一的兼容,略显冗余。
另外就是 oauth 认证了,有整套的认证方案并已工业化,很是成熟了,但对我们而言还是太重,不太适合轻量级的http api,不太可能花费太多的精力去做它的运维工作。
最终选择了轻量级的 ,非常紧凑,开箱即用。
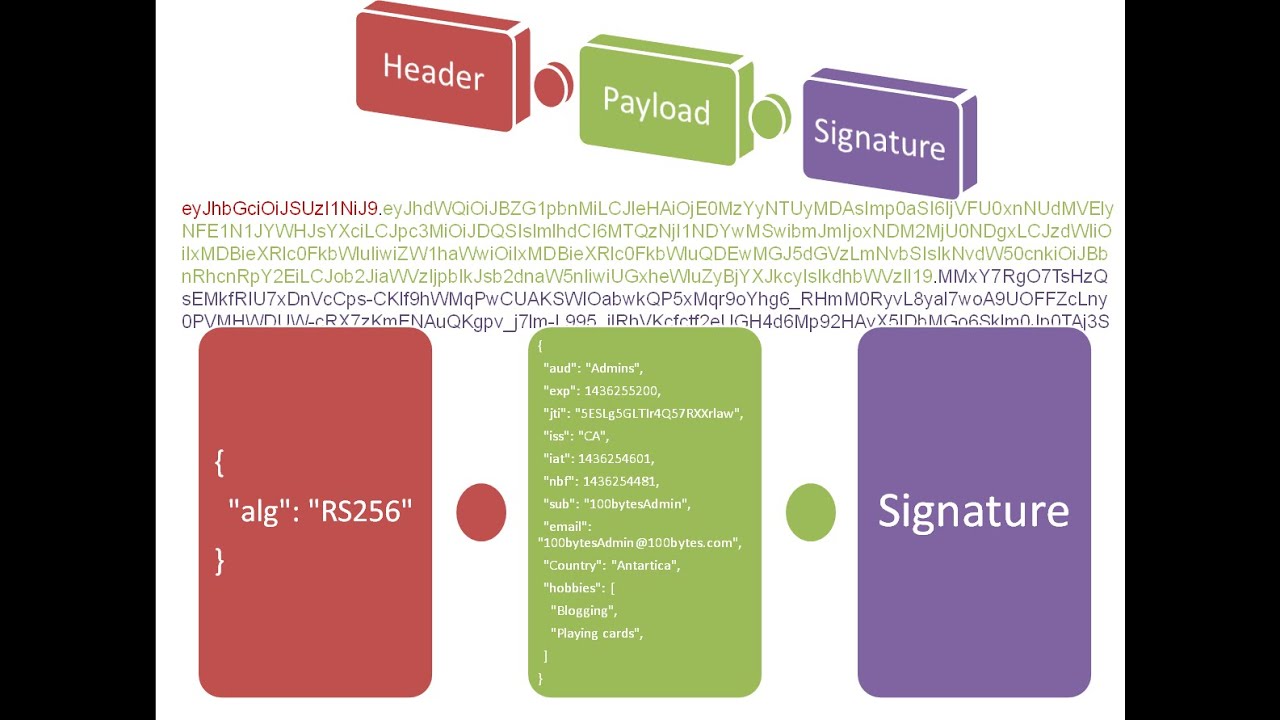
最佳做法是把jwt token放在http请求头部中,不至于和其它参数混淆:
curl -h "authorization: bearer eyjhbgcioijiuzi1niisinr5cci6ikpxvcj9.eyj1awqioii2nyisinv0exblijoxfq.ljkzyriurtqiphsmvojnzz60j0szhpqn3tnqeemspo8" -x get http://localhost/user/info
下面是一副浏览器段的一般认证流程,这与http api认证大体一致:
jwt的lua实现,推荐: https://github.com/skylothar/lua-resty-jwt.git,简单够用。
jwt和lor的结合
jwt需要和业务进行绑定,结合 lor 这个api开发框架提供的中间件机制,可在业务处理之前,在合适位置进行权限拦截。
- 用户需要请求进行授权接口,比如登陆等
- 服务器端会把用户标识符,比如用户id等,存入jwt的payload负荷中,然后生成token字符串,发给客户端
- 客户端收到jwt生成的token字符串,在后续的请求中需要附加在http请求的header中
- 完成认证过程
不同于oauth,jwt协议的自包含特性,决定了后端可以将很多属性信息存放在payload负荷中,其token生成之后后端可以不用存储;下次客户端发送请求时会发送给服务器端,后端获取之后,直接验证即可,验证通过,可以直接读取原先保存其中的所有属性。
下面梳理一下jwt认证和lor的结合。
- 全局拦截,针对所有path,所有http method,这里处理jwt认证,若认证成功,会直接把用户id注入到当前业务处理上下文中,后面的业务可以直接读取当前用户的id值
app:use(function(req, res, next)
local token = ngx.req.get_headers()["authorization"]
-- 校验失败,err为错误代码,比如 400
local payload, err = verify_jwt(token)
if err then
res:status(err):send("bad access token reqeust")
return
end
-- 注入进当前上下文中,避免每次从token中获取
req.params.uid = payload.uid
next()
end)
- 针对具体路径进行设定权限拦截,较粗粒度;比如 /user 只允许已登陆授权用户访问
app:use("/user", function(req, res, next)
if not req.params.uid then
-- 注意,这里没有调用next()方法,请求到这里就截止了,不在匹配后面的路由
res:status(403):send("not allowed reqeust")
else
next() -- 满足以上条件,那么继续匹配下一个路由
end
end)
- 一种是较细粒度,具体到每一个api接口,因为虽然url一致,但不同的http method有时请求权限还是有区别的
local function check_token(req, res, next)
if not req.params.uid then
res:status(403):send("not allowed reqeust")
else
next()
end
end
local function check_master(req, res, next)
if not req.params.uid ~= master_uid then
res:status(403):send("not allowed reqeust")
else
next()
end
end
local lor = require("lor.index")
local app = lor()
-- 声明一个group router
local user_router = lor:router()
-- 假设查看是不需要用户权限的
user_router:get("/feedback", function(req, res, next)
end)
user_router:put("/feedback", check_token, function(req, res, next)
end)
user_router:post("/feedback", check_token, function(req, res, next)
end)
-- 只有管理员才有权限删除
user_router:delete("/feedback", check_master, function(req, res, next)
end)
-- 以middleware的形式将该group router加载进来
app:use("/user", user_router())
......
app:run()
为什么没有选择graphql api ?
我们在上一个项目中对外提供了graphql api,其(在测试环境下)自身提供文档输出自托管机制,再结合方便的调试客户端,确实让后端开发和前端app开发大大降低了频繁交流的频率,节省了若干流量,但前期还是需要较多的培训投入。
但在新项目中,一度想提供graphql api,遇到的问题如下:
- 全新的项目数据结构属性变动太频繁
- 普遍求快,业务模型快速开发、调试
- 大家普遍对graphql api有些抵触,使用json输出格式的http api是约定俗成的习惯选择
毫无疑问,以最低成本快速构建较为完整的app功能,http api json格式是最为舒服的选择。
虽然有些担心服务器端的输出,很多时候还是会浪费掉一些流量,客户端并不能够有效的利用返回数据的所有字段属性。但和进度以及人们已经习惯的http api调用方式相比,又微乎其微了。
小结
当前这一套http api技术堆栈运行的还不错,希望能给有同样需要的同学提供一点点的参考价值 :))
当然没有一成不变的架构模型,随着业务的逐渐发展,后面相信会有很多的变动。但这是以后的事情了,谁知道呢,后面有空再次记录吧~
]]>
在tsung笔记之压测端资源限制篇中说到单一ip地址的服务器最多能够向外发送64k个连接,这个已算是极限了。
但现在我还想继续深入一下,如何突破这个限制呢 ?
如何突破限制
这部分就是要从多个方面去讨论如何如何突破限制单个ip的限制。
0. tsung支持tcp情况
在tsung 1.6.0 中支持的tcp属性有限,全部特性如下:
protocol_options(#proto_opts{tcp_rcv_size = rcv, tcp_snd_size = snd,
tcp_reuseaddr = reuseaddr}) ->
[binary,
{active, once},
{reuseaddr, reuseaddr},
{recbuf, rcv},
{sndbuf, snd},
{keepalive, true} %% fixme: should be an option
].
比如可以配置地址重用:
1. 增加ip地址
这是最为现实、最为方便的办法,向运维的同事多申请若干个ip地址就好。在不考虑其它因素前提下,一个ip地址可以对外建立64k个连接,多个ip就是n * 64k了。这个在tsung中支持的很好。
增加ip可以有多种方式:
- 增加物理网卡方式,一个网卡绑定一个ip地址
- 代价高
- 一个网卡上绑定多个可用的虚拟ip地址
- 比如
ifconfig eth0:2 10.10.10.102 netmask 255.255.255.0 - 虚拟ip必须是真实可用,否则收不到回包数据
- 比如
要是没有足够的可用虚拟ip地址供你使用,或许你需要关注一下后面的
ip_transparent特性描述 :))
2. 考虑linux内核新增so_reuseport端口重用特性
以被压测的一个tcp服务器为例,继续拿网络四元组说事。
{srcip, srcport, targetip, targetport}
- 线上大部分服务器所使用的系统为centos 6系列,所使用系统内核低于3.9
- {srcip, srcport} 确定了本地建立一个连接的唯一性,本地地址的唯一性
- {targetip, targetport}的无法确定唯一,仅仅标识了目的地址
- linux kernel 3.9 支持
so_reuseport端口重用特性 - 网络四元组中,任何一个元素值的变化都会成为一个全新的连接- 真正让网络四元组一起组成了一个网络连接的唯一性
- 理论上可以对外建立的连接数依赖于四个元素可变数值
- totalconnections = nsrcip * nsrcport * ntargetip * ntargetport
线上有部分服务器安装有centos 7,其内核为3.10.0,很自然支持端口重用特性。
针对只有一个ip地址的压测端服务器而言,端口范围也就确定了,只能从目标服务器连接地址上去考虑。有两种方式:
- 目标服务器增加多个可用ip地址,服务程序绑定指定端口即可
- n个ip地址,可用存在 64k * n
- 服务程序绑定多个port,这个针对程序而言难度不大
- 针对单个ip,监听了m个端口
- 可用建立 64k * m 个连接
- 可用这样梳理 , total1 ip connections = 64k * n * m
啰嗦了半天,但目前tsung还没有打算要提供支持呢,怎么办,自己动手丰衣足食吧:
3. 透明代理模式支持
linux kernel 2.6.28提供ip_transparent特性,支持可以绑定不是本机的ip地址。这种ip地址的绑定不需要显示的配置在物理网卡、虚拟网卡上面,避免了很多手动操作的麻烦。但是需要主动指定这种配置,比如下面的c语言版本代码
int opt =1;
setsockopt(server_socket, sol_ip, ip_transparent, &opt, sizeof(opt));
目前在最新即将打包的1.6.1版本中提供了对tcp的支持,也需要翻译成对应的选项,以便在建立网络连接时使用:
 

说明一下:
- ip_transparent没有对应专门的宏变量,其具体值为19
- sol_ip定义宏对应值:0
- 添加socket选项通用格式为:{raw, protocol, optionnum, valuespec}
那么如何让透明代理模式工作呢?
3.1 启用ip_transparent特性
...
3.2 配置可用的额外ip地址
那么这些额外的ip地址如何设置呢?
可以为client元素手动添加多个可用的ip地址
...... 可以使用新增的
iprange特性
但是需要确保:
- 这些ip地址目前都没有被已有服务器在使用
- 并且可以被正常绑定到物理/虚拟网卡上面
- 完全可用
3.3 配置路由规则支持
假设我们的tsung_client1这台压测端服务器,绑定所有额外ip地址到物理网卡eth1上,那么需要手动添加路由规则:
ip rule add iif eth1 tab 100
ip route add local 0.0.0.0/0 dev lo tab 100
这个支持压测端绑定同一网段的可用ip地址,比如压测端ip为172.16.247.130,172.16.247.201暂时空闲的话,那我们就可以使用172.16.89.201这个ip地址用于压测。此时不要求被压测的服务器配置什么。
3.4 进阶,我们使用一个新的网段专用于测试
比如 10.10.10.0 这个段的ip机房暂时没有使用,那我们专用于压测使用,这样一台服务器就有了250多个可用的ip地址了。
压测端前面已经配置好了,现在需要为被压测的服务器添加路由规则,这样在响应数据包的时候能够路由到压测端:
route add -net 10.10.10.0 netmask 255.255.255.0 gw 172.16.247.130
设置完成,可以通过route -n命令查看当前所有路由规则:
 

在不需要时,可以删除掉:
route del -net 10.10.10.0 netmask 255.255.255.0
小结
梳理了以上所能够想到的方式,以尽可能突破单机的限制,核心还是尽可能找到足够多可用的ip地址,利用linux内核特性支持,程序层面绑定尽可能多的ip地址,建立更多的对外连接。当然以上没有考虑类似于cpu、内存等资源限制,实际操作时,还是需要考虑这些资源的限制的。
]]>
总是说细节、理论,会让人不胜其烦。我们使用tsung来一次100万用户压测的吧,或许能够引起好多人的兴趣 :))
下面,我根据在公司分享的ppt《分布式百万用户压测你的业务》,贴出其中的关键部分,说明进行一次100w(即1m)用户压测的执行步骤。
如何做分布式百万用户的压测 ?
假定面向小白用户,因此才有了下面可执行的10个步骤用于开展分布式百万用户。
 

看着步骤很多,一旦熟悉并掌握之后,中间可以省却若干。
1. 阅读tsung文档
 

建议大家在使用tsung之前,花费一点时间阅读完整个用户手册,虽然是英文的,阅读起来也不复杂。读完之后,我们也就知道如何做测试了,遇到的大部分问题,也能够在里面找到答案。
- 凯发k8网页登录官网:
- 在线手册:
2 确定压测目标
 

- 要对线上系统压测100万用户,为了尽可能降低线上服务器负载压力,这里设置每秒产生500个用户,将在60分钟内产生完毕
- 要压测的服务器所填写网络访问地址可以根据需要填写多个
3. 计算所需要从机数量
 

 

 

 

 

 

- tsung为主从模型,我们启动了主节点之后,主节点会按需启动从节点
- 设定所用服务器可用内存大于3g,并且都只有一个ip地址
- 一台从机可用模拟6万用户,需要17台从机
- 若资源充足,可以少用几台服务器,配置多个ip地址
- 找到所需要的压测用服务器,在资源层面满足测试测试集群需要,这个是关键
4. 部署tsung
 

因为tsung依赖于erlang,因此需要首先安装:
wget https://packages.erlang-solutions.com/erlang-solutions-1.0-1.noarch.rpm
rpm -uvh erlang-solutions-1.0-1.noarch.rpm
sudo yum install erlang
然后再是安装tsung,建议直接使用tsung 1.6.0修改版,主要提供ip只连支持(具体细节,可参考这里 http://www.blogjava.net/yongboy/archive/2016/07/28/431354.html ):
git clone https://github.com/weibomobile/tsung-1.6.0.git
./configure --prefix=/usr/local
make install
5. 下载ssh替代者-tsung—rsh
 

为什么要替换掉ssh,主要原因:
- ssh在一般网络机房环境内服务器之间被禁止连接通信,这会导致主节点无法启动从节点,无法建立分布式压测集群
- 就算是ssh没被禁用,主从之间需要设置免秘钥ssh登录方式,十分麻烦
可进一步参考:tsung笔记之分布式增强跳出ssh羁绊篇。
6. 编写压测内容
 

 

 

要把业务定义的所有会话内容完整的整理映射成tsung的会话内容,因为用户行为很复杂,也需要我们想法设法去模拟。
其实,演示所使用的是私有协议,可以参考 tsung笔记之插件编写篇 。
当完成压测会话内容之后,users_100w.xml文件已经填写完毕,我们可以开始压测了。
7. 运行tsung
 

- -f 10.10.10.10 主节点ip地址,ip直连特性
- -rsh rsh_client.sh 远程终端,ssh通道被替换
- -s 压测端启用erlang smp特性,按需使用所有cpu核心
我们启动了从节点,然后从节点被启动,开始执行具体压测任务了。
8. 压测过程中,我们该做什么
 

紧密关注服务器服务状态、资源占用等情况就对了,最好还要作为一个终端用户参与到产品体验中去。
9. 压测结束,生成tsung报表
 

tsung压测结束之后,不会主动生成压测结果报表的,需要借助于 tsung_stats.pl perl脚本生成,要查阅可借助python生成临web站点,浏览器打开即可。
10. 回顾和总结
 

小结
其实,一旦熟悉并掌握tsung之后,步骤1-6都可以节省了,循环执行步骤7-10。
你若以为仅仅只是谈论tsung如何做1m用户压测,那就错了,只要机器资源够,这个目标就很容易实现。我们更应该关注,我们压测的目的是什么,我们应该关注什么,这个应该形成一个完整可循环过程,驱动着系统架构健康先前发展。
]]>
tsung对具体协议、通道的支持,一般以插件形式提供接口,接口不是很复杂,插件也很容易编写,支持协议多,也就不足为怪了。
下面首先梳理一下当前tsung 1.6.0所有内置插件,然后为一个名称为qmsg的私有二进制协议编写插件, 运行qmsg服务器端程序,执行压力测试,最后查看测试报告。
已支持插件梳理
tsung 1.6.0支持的协议很多,简单梳理一下:
 

- 压测的协议首先需要支持xml形式配置,配置内容需要
tsung_config_protocolname模块解析- 存放在tsung_controller目录下
- 其次是tsung client端也要插件
ts_protocolname模块支持数据操作- 存放在tsung目录下
- 同时在tsung项目examples目录下也给出了已支持协议配置简单示范xml文件
已经支持协议简单说明:
- amqp,advanced message queuing protocol缩写,只要支持高级消息队列协议的应用,都可以用来做压测,比如rabbitmq,activemq等
- http,基本协议,构建于http协议之上的,还有类似于bosh,webdav等上层业务协议
- jabber,也称之为xmpp,支持的相当丰富,除了tcp/ssl,还可以通过websocekt进行传递
- raw,针对原始类型消息,不做编解码处理,直接在tcp / udp / ssl等传输层中传递,这个对部分私有协议,比较友好,不用写单独的编解码处理,直接透传好了
- shell,针对linux/unix终端命令调用进行压测,这种场景比较小众
- fs,filesystem缩写,针对文件系统的读写性能进行压测
- job,针对任务调度程序进行的压测,比如pbs/torquelsf、oar等
tsung插件工作机制
粗一点来看tsung插件的工作流程(点击可以看大图):
放大一些(引用 博客图片,相当赞!):
为什么要编写插件
tsung针对通用协议有支持,若是私有或不那么通用的协议,就不会有专门的插件支持了,那么可选的有两条路子:
- 使用raw模式发送原始消息,需要自行组装
- 自己编写插件,灵活处理编解码
既然谈到了插件,我们也编写一个插件也体验一下编写插件的过程。
qmsg协议定义
假设一个虚拟场景,打造一个新的协议qmsg,二进制格式组成:
 

这种随意假象出来的格式,不妨称作为qmsg(q可爱形式的message)协议,仅作为demo演示而存在。简单场景:
- 用户发言,包含用户id和发言内容
- user id,32位自然数类型
- 发言为文字内容,字符串形式,长度不固定
- 组装后的请求体为二进制协议格式
pocketlen:**##userid usercomment##**
- 服务器端返回用户id和一个幸运数字(32位表示)
pocketlen:**##userid randomcode##**
为了卡哇伊一些,多了一些点缀的“**####**”符号。
编写一个完整插件
这里基于tsung 1.6.0版本构建一个qmsg插件,假定你懂一些erlang代码,以及熟悉tsung一些基本概念。
0. 创建一个项目
要创建tsung的一个qmsg插件项目,虽没有固定规范,但按照已有格式组织好代码层级也是有必要的。
├── include
│ └── ts_qmsg.hrl
├── src
│ ├── tsung
│ │ └── ts_qmsg.erl
│ └── tsung_controller
│ └── ts_config_qmsg.erl
└── tsung-1.0.dtd
1. 创建配置文件
tsung的压测以xml文件驱动,因此需要界定一个qmsg插件形式的完整会话的xml呈现,比如:
hello tsung plugin
this is a tsung plugin
ts_qmsg,会话类型所依赖协议模拟客户端实现text request元素内uid为属性
此时,你若直接在xml文件中编辑,会遇到校验错误。
2. 更新dtd文件
tsung的xml文件依赖tsung-1.0.dtd文件进行校验配置是否有误,需要做对dtd文件做修改,以支持所添加新的协议。
在tsung-1.0.dtd项目中,最小支持:
- session元素type属性中添加上
ts_qmsg - request元素处添加
qmsg: - 添加qmsg元素定义:
完整内容,可参考
tsung_plugin_demo/tsung-1.0.dtd文件。
3. 头文件 include/ts_qmsg.hrl
头文件include/ts_qmsg.hrl定义数据保存的结构(也称之为记录/record):
-record(qmsg_request, {
uid,
data
}).
-record(qmsg_dyndata, {
none
}
).
- qmsg_request: 存储从xml文件解析的qmsg请求数据,用于生成压力请求
- qmsg_dyndata: 存储动态参数(当前暂未使用到)
4. xml文件解析
ts_config_qmsg.erl文件,用于解析和协议qmsg关联的配置:
- 只需要实现parse_config/2唯一方法
- 解析xml文件中所配置qmsg协议请求相关配置
- 被ts_config:parse/1在遇到qmsg协议配置时调用
备注:
- 若要支持动态替换,需要的字段以字符串形式读和存储
5. ts_qmsg.erl
ts_qmsg.erl模块主要提供qmsg协议的编解码的完整动作, 以及当前协议界定下的用户会话属性设定。
首先需要实现接口ts_plugin规范定义的所有需要函数,定义了参数值和返回值。
-behavior(ts_plugin).
...
-export([add_dynparams/4,
get_message/2,
session_defaults/0,
subst/2,
parse/2,
parse_bidi/2,
dump/2,
parse_config/2,
decode_buffer/2,
new_session/0]).
相对来说,核心为协议的编解码功能:
get_message/2,构造请求数据,编码成二进制,上层ts_client模块通过socket连接发送给目标服务器parse/2,(当对响应作出校验时)从原始socket上返回的数据进行解码,取出协议定义业务内容
这部分代码可以参考 tsung_plugin_demo/src/tsung/ts_client.erl 文件。
6. 如何编译
虽然理论上可以单独编,生成的beam文件直接拷贝到已经安装的tsung对应目录下面,但实际上插件编写过程中要依赖多个tsung的hrl文件,这造成了依赖路径问题。采用直接和tsung打包一起部署,实际操作上有些麻烦,
为了节省体力,使用一个shell脚本 - build_plugin.sh,方便快速编译、部署:
# !/bin/bash
cp tsung-1.0.dtd $1/
cp include/ts_qmsg.hrl $1/include/
cp src/tsung_controller/ts_config_qmsg.erl $1/src/tsung_controller/
cp src/tsung/ts_qmsg.erl $1/src/tsung/
cd $1/
make uninstall
./configure --prefix=/usr/local
make install
这里指定安装tsung的指定目录为
/usr/local,可以根据需要修改
需要提前准备好tsung-1.6.0目录:
wget http://tsung.erlang-projects.org/dist/tsung-1.6.0.tar.gz
tar xf tsung-1.6.0.tar.gz
在编译qmsg插件脚本时, 指定一下tsung-1.6.0解压后的路径即可:
sh build_plugin.sh /your_path/tsung-1.6.0
后面嘛,就等着自动编译和安装呗。
启动qmsg协议的压测
1. 首先启动qmsg服务器端程序
既然有压测端,就需要一个qmsg协议处理的后端程序qmsg_server.erl,用于接收客户端请求,获得用户id值之后,生成一个随机数字,组装成二进制协议,然后发给客户端,这就是全部功能。
这个程序,简单一个文件,在 tsung_plugin_demo目录下面,编译运行, 默认监听5678端口:
erlc qmsg_server.erl && erl -s qmsg_server start
另外,还提供了一个手动调用接口,方便在erlang shell端调试:
%% 下面为
qmsg_server:sendmsg(1001, "这里是用户发言").
启动之后,监听地址 *: 5678
源码见:tsung_plugin_demo/qmsg_server.erl
2. 编写qmsg压测xml配置文件
因为是演示示范,一台linxu主机上就可以进行了:
- 连接本机的 127.0.0.1:5678
- 最多产生10个用户,每秒产生1个,压力负载设置的很低
- 两个不同类型会话,比重10% 90% = 100%
qmsg-subst-example会话使用了用户id个和用户发言内容自动生成机制
hello tsung plugin qmsg!
haha : %%_random_txt%%
this is a tsung plugin
这部分内容,请参考 tsung_plugin_demo/tsung_qmsg.xml 文件。
3. 执行压力测试
当qmsg的压力测试配置文件写好之后,可以开始执行压力测试了:
tsung -f tsung_qmsg.xml start
其输出:
tarting tsung
log directory is: /root/.tsung/log/20160621-1334
[os_mon] memory supervisor port (memsup): erlang has closed
[os_mon] cpu supervisor port (cpu_sup): erlang has closed
其中, 其日志为:/root/.tsung/log/20160621-1334。
4. 查看压测报告
进入其生成压测日志目录,然后生成报表,查看压测结果哈:
cd /root/.tsung/log/20160621-1334
/usr/local/lib/tsung/bin/tsung_stats.pl
echo "open your browser (url: http://ip:8000/report.html) and vist the report now :))"
/usr/bin/python -m simplehttpserver
嗯,打开你的浏览器,输出所在服务器的ip地址,就可以看到压测结果了。
小结
以上代码已经放入github仓库:。
实际业务的私有协议内容要比上面demo出来的qmsg复杂的多,但其私有协议插件编写,如上面所述几个步骤,按照规范编写,单机测试,然后延伸到分布式集群,完整流程都是一致的。
嗯,搞定了插件,就可以对系统愉快地进行压测了 :))
]]>
压力测试和监控分不开,监控能够记录压测过程中状态,方便问题跟踪、定位。本篇我们将讨论对压测客户端tsung client的监控,以及对被压测服务器的资源占用监控等。同时,也涉及到tsung运行时的实时诊断方式,这也是对tsung一些运行时状态的主动监控。
压测客户端的监控
压测端(指的是tsung client)会收集每一个具体模拟终端用户(即ts_client模块)行为数据,发送给主节点(tsung_controller),供后面统计分析使用。
 

- ts_client模块调用ts_mon,而ts_mon又直接调用ts_mon_cache,有些绕,不直观(逻辑层面可忽略掉ts_mon)
- count为计数器,sum表示各项累加值,sample和sample_counter计算一次统计项的平均值&标准差
- tsung.dump文件一般不会创建&写入,除非你在tsung.xml文件中指定需要dump属性为true,压测数据量大时这个会影响性能
match.log仅仅针对http请求,默认不会写入,除非在http压测指定
200ok 从节点tsung client所记录日志、需要dump的请求-响应数据,都会交由tsung_controller处理
ts_mon_cache,接收到数据统计内存计算,每500毫秒周期分发给后续模块,起到缓冲作用
ts_stats_mon模块接收数据进行内存计算,结果写入由ts_mon触发
ts_mon负责统计数据最每10秒定时写入各项统计数据到tsung.log文件,非实时,可避免磁盘io开销过大问题
tsung/src/tsung_controller/tsung_controller.app.in对应{dumpstats_interval, 10000}- 可以在运行时修改
tsung.log文件汇集了客户端连接、请求、完整会话、页面以及每一项的sum操作统计的完整记录,后续perl脚本报表分析基于此
ts_mon模块处理tsung.log的最核心模块,全局唯一进程,标识为
{global, ts_mon}
比如某次单机50万用户压测tsung.log日志片段:
# stats: dump at 1467620663
stats: users 7215 7215
stats: {freemem,"os_mon@yhg162"} 1 11212.35546875 0.0 11406.32421875 11212.35546875 11346.37109375 2
stats: {load,"tsung_controller@10.10.10.10"} 1 0.0 0.0 0.01171875 0.0 0.01171875 2 17,1 top
stats: {load,"os_mon@yhg162"} 1 2.3203125 0.0 3.96875 0.9609375 2.7558736313868613 411
stats: {recvpackets,"os_mon@yhg162"} 1 5874.0 0.0 604484 5874 319260.6024390246 410
stats: {sentpackets,"os_mon@yhg162"} 1 8134.0 0.0 593421 8134 293347.0707317074 410
stats: {cpu,"os_mon@yhg162"} 1 7.806645016237821 0.0 76.07377357701476 7.806645016237821 48.0447587419309 411
stats: {recvpackets,"tsung_controller@10.10.10.10"} 1 4164.0 0.0 45938 4164 24914.798543689314 412
stats: {sentpackets,"tsung_controller@10.10.10.10"} 1 4182.0 0.0 39888 4182 22939.191747572815 412
stats: {cpu,"tsung_controller@10.10.10.10"} 1 0.575191730576859 0.0 6.217097016796189 0.575191730576859 2.436491628709831 413
stats: session 137 2435928.551725737 197.4558174045777 2456320.3908691406 2435462.9838867188 2436053.875557659 499863
stats: users_count 0 500000
stats: finish_users_count 137 500000
stats: connect 0 0 0 1004.4912109375 0.278076171875 1.480528250488281 500000
stats: page 139 12.500138756182556 1.1243565417115737 2684.760009765625 0.43115234375 16.094989098940804 30499861
stats: request 139 12.500138756182556 1.1243565417115737 2684.760009765625 0.43115234375 16.094989098940804 30499861
stats: size_rcv 3336 3386044720
stats: size_sent 26132 6544251843
stats: connected -139 0
stats: error_connect_timeout 0 11
tsung.log日志文件可由tsung_stats.pl脚本提取、分析、整理成报表展示,其报表的一个摘要截图:
 

异常行为的收集
当模拟终端遇到网络连接超时、地址不可达等异常事件时,最终也会发给主节点的ts_mon模块,保存到tsung.log文件中。
这种异常记录,关键词前缀为 **error_**:
- 比如ts_client模块遇到连接超时会汇报
error_connect_timeout错误 - 系统的可用端口不够用时(创建与压测服务器连接数超出可用段限制)上报
error_connect_eaddrinuse错误
errors报表好比客户端出现问题晴雨表,再加上tsung输出log日志文件,很清楚的呈现压测过程中出现的问题汇集,方便问题快速定位。
 

被压测服务器的监控
当前tsung提供了3种方式进行监控目标服务器资源占用情况:
- erlang
- snmp
- munin
大致交互功能,粗略使用一张图表示:
 

- tsung_controller主节点会被强制启用监控
- snmp方式,客户端作为代理主动注册并连接开放snmp的服务器,snmp安装针对新手来说比较复杂
- munin采用c/s模式,自身要作为客户端连接被压测服务器上能够安装munin server
- erlang方式,本身代理形式监控服务器资源占用,满足条件很简单:
- 需要能够自动登录连接
- 并且安装有erlang运行时环境,tsung_controller方便启动监控节点
- 采用远程加载方式业务代码,省去被监控端部署的麻烦
- 现实情况下,我一般采用一个脚本搞定自动部署监控部署客户端,自动打包可移植的erlang,简单绿色,部署方便
- 提供监控采样数据包括 cpu/memory/load/socket sent&recv
- 所有监控数据都会被发送给ts_mon模块,并定时写入到tsung.log文件中
看一个最终报表部分呈现吧:
 

tsung对服务器监控采样手机数据不是很丰富,因为它面向的更为通用的监控需求。
更深层次、更细粒度资源监控,就需要自行采集、自行分析了,一般在商业产品在这方面会有更明确需求。
日志收集
和前面讲到的终端行为数据采集和服务器端资源监控行为类似,tsung运行过程中所产生日志被存储到主节点。
tsung使用error_logger记录日志,主节点tsung_controller启动之后,会并发启动tsung client从节点,换句话来说tsung client从节点是由主节点tsung_controller创建,这个特性决定了tsung client从节点使用error_logger记录的日志都会被重定向到主节点tsung_controller所在服务器上,这个是由erlang自身独特机制决定。
因此,你在主节点log目录下能够看到具体的日志输出文件,也就水到渠成了。因为erlang天生分布式基因,从节点error_logger日志输出透明重定向到主节点,不费吹灰之力。这在其他语言看来,确实完全不可能轻易实现的。
基于error_logger包装日志记录,需要一个步骤:
- 设置输出到文件系统中
error_logger:tty(false) - 设定输出的文件目录
error_logger:logfile({open, logfile}) - 包装日志输出接口
?debug/?debugf/?log/?logf/ - 最终调用包装的error_logger接口
debug(from, message, args, level) ->
debug_level = ?config(debug_level),
if
level =< debug_level ->
error_logger:info_msg("~20s:(~p:~p) " message,
[from, level, self()] args);
true ->
nodebug
end.
和大部分日志框架设定的日志等级一致,emergency > critical > error > warning > notice (default) > info > debug,从左到右,依次递减。
需要注意事项,error_logger语义为记录错误日志,只适用于真正的异常情况,并不期望过多的消息量的处理。
若当一般业务调试类型日志量过多时,不但耗费了大量内存,网络/磁盘写入速度跟不上生产速度时,会导致进程堵塞,严重会拖累整个应用僵死,因此需要在tsung.xml文件中设置至少info级别,至少默认的notice就很合适。
tsung运行时诊断/监控
tsung在运行时,我们可以remote shell方式连接登录进去。
为了连接方便,我写了一个脚本 connect_tsung.sh,只需要传入tsung节点名称即可:
# !/bin/bash
## 访问远程tsung节点 sh connect\_tsung.sh tsung\_controller@10.10.10.10
host=`ifconfig | grep "inet " | grep -v "127.0.0.1" | head -1 | awk '{print $2}' | cut -d / -f 1`
if [ -z $host ]; then
host = "127.0.0.1"
fi
erl -name tmp\_$random@$host -setcookie tsung -remsh $1
需要安装有erlang运行时环境支持
当然,要向运行脚本,你得知道tsung所有节点名称。
如何获得tsung节点名称
其实有两种方式获得tsung节点名称:
- 直接连接tsung_controller节点获得
- 若是ip形式,
sh connect_tsung.sh tsung_controller@10.10.10.10 - 若是hostname形式,可以这样:
sh connect_tsung.sh tsung_controller@tsung_master_hostname - 成功进入之后,输入
nodes().可以获得完整tsung client节点列表
- 若是ip形式,
- 启动tsung时生成日志所在目录,可以看到类似日志文件:
- tsung client端产生日志单独存放,格式为
节点名称.log - eg: ,那么节点名称为tsung15@10.10.10.113
- 可以直接连接:
sh connect_tsung.sh tsung15@10.10.10.ll3
- tsung client端产生日志单独存放,格式为
如何诊断/监控tsung运行时
其实,这里仅仅针对使用erlang并且对tsung感兴趣的同学,你都能够进来了,那么如何进行查看、调试运行时tsung系统运行情况,那么就很简单了。推荐使用 库,包括内存占用,函数运行堆栈,cpu资源分配等,一目了然。
若问,tsung启动时如何添加recon依赖,也不复杂:
- 每一个运行tsung的服务器拷贝已经编译完成的recon项目到指定目录
tsung_controller主节点启动时,指定recon依赖库位置
tsung -x /your_save_path/recon/ebin/ ...
说一个用例,修改监控数据每10秒写入tsung.log文件时间间隔值,10秒修改为5秒:
application:set_env(tsung_controller, dumpstats_interval, 5000).
执行之后,会立刻生效。
小结
总结了tsung主从监控,以及服务器端监控部分,以及运行时监控等。提供的被压测服务器监控功能很粗,仅收集cpu、内存、负载、接收数据等类型峰值,具有一般参考意义。但基于tsung构建的、或类似商业产品,一般会有提供专门数据收集服务器,但对于开源的应用而言,需要兼顾通用需求,也是能够理解的。
]]>
前面说到设计一个小型的c/s类型远程终端套件以替换ssh,并且已经应用到线上。这个问题,其实不是tsung自身的问题,是外部连接依赖问题。
tsung在启动分布式压测时,主节点tsung_controller要连接的从机必须要填写主机名,主机名没有内网dns服务器支持解析的情况下(我所经历互联网公司很少有提供支持的),只好费劲在/etc/hosts文件中填写主机名称和ip地址的映射关系,颇为麻烦,尤其是要添加一批新的压测从机或从机变动频率较大时。
那么如何解决这些问题呢,让tsung在复杂的机房内网环境下,完全基于ip进行直连,这将是本文所讨论的内容。
预备知识
完全限定域名
完全限定域名,缩写为fqdn (fully qualified domain name),:
一种用于指定计算机在域层次结构中确切位置的明确域名。
一台特定计算机或主机的完整 internet 域名。fqdn 包括两部分:主机名和域名。例如 mycomputer.mydomain.com。
一种包含主机名和域名(包括顶级域)的 url。例如,www.symantec.com 是完全限定域名。其中 www 是主机,symantec 是二级域,.com 是顶级域。fqdn 总是以主机名开始且以顶级域名结束,因此 也是一个 fqdn。
若机器主机名为内网域名形式,并且支持dns解析,方便其它服务器可通过该主机名直接找到对应ip地址,能够 ping -c 3 机器域名 通,那么机器之间能够容易找到对方。
服务器hostname的命名,若不是域名形式,简短名称形式,比如“yk_mobile_dianxin_001”,一般内网的dns服务器不支持解析,机器之间需要互相在/etc/hosts文件建立彼此ip地址映射关系才能够互相感知对方。
erlang节点名称的规则
因为tsung使用erlang编写,erlang关于节点启动名称规定,也是tsung需要面对的问题。
erlang节点名称一般需要遵循两种格式:
- 一般名称(也称之为短名称)形式,不包含“.”字符,比如
erl -name tsun_node - 完全限定域名形式
- 域名形式,比如
erl -name tsun_node.youdomain.com - ip形式,比如
erl -name 10.10.10.103
- 域名形式,比如
tsung处理方式:
- 若非特别指定,一般默认为短名称形式
- 启动时可以通过
-f参数指定使用完全限定域名形式
获得ip地址
主机名称无论是完全限定域名形式,还是简单的短名称形式,当别的主机需要通过主机名访问时,系统层面需要通过dns系统解析成ip地址才能够进行网络连接。当内网dns能够解析出来ip来,没有什么担心的;(短名称)解析不出来时,多半会通过写入到系统的 /etc/hosts 文件中,这样也能够解析成功。
一般机房内网环境,主机名称大都是短名称形式,若需分布式,每一个主机之间都要能够互相联通,最经济做法就是直接使用ip地址,可避免写入大量映射到 hosts 文件中,也会避免一些隐患。
主节点启动增加ip支持
默认情况下,tsung master主节点名称类似于tsung_controller@主机名:
- 节点名称前缀默认为:
tsung_controller(除非在tsung启动时通过-i指定前缀) - 一般主机名都是字符串形式(
hostname命令可设置主机名) - 可将主机名称设置为本机ip,但不符合人类认知惯性
既然tsung主节点默认对ip节点名称支持不够,改造一下tsung/tsung.sh.in脚本。
tsung启动时-f参数为指定使用完全限定域名(fqdn)形式,不支持携带参数。若要直接传递ip地址,类似于:
-f your_ip
修改tsung.sh.in,可以传递ip地址,手动组装节点名称:
f) nametype="-name"
server_ip=$optarg
if [ "$server_ip" != "" ]; then
controller_extends="@$server_ip"
fi
;;
修改不复杂,更多细节请参考:
启动tsung时,指定本地ip:
tsung -f 10.10.10.10 -f tsung.xml start
tsung_controller目前节点名称已经变为:
-name tsung_controller@10.10.10.10
嗯,目标达成。
从节点主机增加ip配置
给出一个节点client50配置:
tsung master想访问client50,需要提前建立client50与ip地址的映射关系:
echo "10.10.10.50 client50" >> /etc/hosts
host属性默认情况下只能填写长短名称,无法填写ip地址,为了兼容已有规则,修改tsung-1.0.dtd文件为client元素新增一个hostip属性:
修改src/tsung_controller/ts_config.erl文件,增加处理逻辑,只有当主节点主机名为ip时才会取hostip作为主机名:
{ok, masterhostname} = ts_utils:node_to_hostname(node()),
case {ts_utils:is_ip(masterhostname), ts_utils:is_ip(host), ts_utils:is_ip(hostip)} of
%% must be hostname and not ip:
{false, true, _} ->
io:format(standard_error,"error: client config: 'host' attribute must be a hostname, " "not an ip ! (was ~p)~n",[host]),
exit({error, badhostname});
{true, true, _} ->
%% add a new client for each cpu
lists:duplicate(cpu,#client{host = host,
weight = weight/cpu,
maxusers = maxusers});
{true, _, true} ->
%% add a new client for each cpu
lists:duplicate(cpu,#client{host = hostip,
weight = weight/cpu,
maxusers = maxusers});
{_, _, _} ->
%% add a new client for each cpu
lists:duplicate(cpu,#client{host = host,
weight = weight/cpu,
maxusers = maxusers})
end
嗯,现在可以这样配置从节点了,不用担心tsung启动时是否附加-f参数了:
其实,只要你确定只使用主节点主机名为ip地址,可以直接设置host属性值为ip值,可忽略hostip属性,但这以牺牲兼容性为代价的。
为了减少/etc/hosts大量映射写入,还是推荐全部ip形式,这种形式适合tsung分布式集群所依赖服务器的快速租赁模型。
源码地址
针对tsung最新代码增加的ip直连特性所有修改,已经放在github上:
。
并且已经递交pull request: 。
比较有意思的是,有这样一条评论:
 

针对tsung 1.6.0修改版
最近一次发行版是tsung 1.6.0,这个版本比较稳定,我实际压测所使用的就是在此版本上增加ip直连支持(如上所述),已经被单独放入到github上:
至于如何安装,git clone到本地,后面就是如何编译tsung的步骤了,不再累述。
小结
若要让ip直连特性生效,再次说明启用步骤一下:
- tsung.xml文件配置从机hostip属性,或host属性,填写正确ip
- tsung启动时,指定本机可用ip地址:
tsung -f your_available_ip -f tsung.xml ... start
ip直连,再配合前面所写ssh替换方案,可以让tsung分布式集群在复杂网络机房内网环境下适应性向前迈了一大步。
2016-08-06 更新此文,增加tsung 1.6.0修改版描述
]]>
erlang天生支持分布式环境,tsung框架的分布式压测受益于此,简单轻松操控子节点生死存亡、派发任务等不费吹灰之力。
tsung启动分布式压测时,主节点tsung_controller默认情况下需要通过ssh通道连接到远程机器上启动从节点,那么问题便来了,一般互联网公司基于跳板/堡垒机/网关授权方式访问机房服务器,那么ssh机制失效,并且被明令禁止。ssh不通,tsung主机启动不了从机,分布式更无从谈起。
那么如何解决这个问题呢,让tsung在复杂的机房网络环境设定下更加如鱼得水,将是本文所讨论的内容。
rsh:remote shell
rsh,remote shell缩写,维基百科上英文解释:。作为一个终端工具,linux界鸟哥曾经写过 。
在centos下安装也简单:
yum install rsh
erlang借助于rsh命令行工具通过ssh通道连接到从节点启动tsung应用,下面可以看到rsh工具本身失去了原本的含义,类似于exec命令功效。
比如erlang主节点(假设这个服务器名称为node_master,并且已经在/etc/hosts文件建立了ip地址映射)在启动时指定rsh的可选方式为ssh:
erl -rsh ssh -sname foo -setcookie mycookie
启动之后,要启动远程主机节点名称为node_slave的子节点:
slave:start(node_slave, bar, "-setcookie mycookie").
上面erlang启动从节点函数,最终被翻译为可执行的shell命令:
ssh node_slave erl -detached -noinput -master foo@node_master -sname bar@node_slave -s slave slave_start foo@node_master slave_waiter_0 -setcookie mycookie
erl命令erlang的启动命令,要求主机node_slave自身也要安装了erlang的运行时环境才行。
从节点的启动命令最终依赖于ssh连接并远程执行,其通用一般格式为:
ssh hostname/ip command
这就是基于erlang构建的tsung操控从节点启动的最终实现机制。
其它语言中,master启动slave也是如此机制
ssh为通用方案,但不是最好的方案
业界选用机制连接远程unix/linux服务器主机,分布式环境下要能够自由免除密码方式启动远程主机上(这里指的是内部lan环境)应用,一般需要设置公钥,需要传递公钥,需要保存到各自机器上,还有经常遇到权限问题,很是麻烦,这是其一。若要取消某台服务器登陆授权,则需要被动修改公钥,也是不够灵活。
另外一般互联网公司处于安全考虑都会禁止公司内部人员直接通过ssh方式登录到远程主机进行操作,这样导致ssh通道失效,tsung主机通过ssh连接到从机并执行命令,也就不可能了。
其实,在基于分布式压测环境下,快速租赁、快速借用/归还的模型就很适合。一般公司很少会存在专门用于压测的大量空闲机器,但是线上会运行着当前负载不高的服务器,可以拿来用作压测客户端使用,用完就归还。因为压测不会是长时间运行的服务,其为短时间行为。这种模式下就不适合复杂的ssh公钥满天飞,后期忘记删除的情况,在压测端超多的情况下,无疑也将造成运维成本激增,安全性降低等问题。
ssh替换方案:一种快速租赁模式远程终端方案
现在需要寻找一种新的代替方案,一种适应快速租赁的远程终端实现机制。
替换方案要求点
- 类似于ssh server,监听某个端口,能够执行传递过来的命令
- 能够根据ip地址授权,这样只有tsung master才能够访问从节点,从节点之间无法直接对连
- 需要接受一些操控指令,可以判断是否存活
- 一到两个脚本/程序搞定,尽量避免安装,开箱即用
- 总之配置、操作一定要简单,实际运维成本一定要低
没找到很轻量的实现,可以设计并实现这样一种方案。
服务器端守护进程
轻量级服务端守护进程 = 一个监控端口的进程(rsh_daemon.sh) 执行命令过滤功能(rsh_filter)
rsh_daemon.sh 负责守护进程的管理:
- 基于centos 6/7默认安装的
ncat程序 - 主要用于管理19999端口监听
- start/stop/restart 负责监控进程启动、关闭
- status 查看进程状态
- kill 提供手动方式关闭并删除掉自身
rsh_filter用于检测远程传入命令并进行处理- 接收ping指令,返回pong
- 执行erlang从节点命令,并返回 done 字符串
- 对不合法命令,直接关闭
rsh_daemon.sh代码很简单:
#!/bin/bash
# the script using for start/stop remote shell daemon server to replace the ssh server
port=19999
filter=~/tmp/_tmp_rsh_filter.sh
# the tsung master's hostname or ip
tsung_controller=tsung_controller
special_path=""
prog=`basename $0`
prepare() {
cat << eof > $filter
#!/bin/bash
erl_prefix="erl"
while true
do
read cmd
case \$cmd in
ping)
echo "pong"
exit 0
;;
*)
if [[ \$cmd == *"\${erl_prefix}"* ]]; then
exec $special_path\${cmd}
fi
exit 0
;;
esac
done
eof
chmod a x $filter
}
start() {
num=$(ps -ef|grep ncat | grep ${port} | grep -v grep | wc -l)
if [ $num -gt 0 ];then
echo "$prog already running ..."
exit 1
fi
if [ -x "$(command -v ncat)" ]; then
echo "$prog starting now ..."
ncat -4 -k -l $port -e $filter --allow $tsung_controller &
else
echo "no exists ncat command, please install it ..."
fi
}
stop() {
num=$(ps -ef|grep ncat | grep rsh | grep -v grep | wc -l)
if [ $num -eq 0 ]; then
echo "$prog had already stoped ..."
else
echo "$prog is stopping now ..."
ps -ef|grep ncat | grep rsh | grep -v grep | awk '{print $2}' | xargs kill
fi
}
status() {
num=$(ps -ef|grep ncat | grep rsh | grep -v grep | wc -l)
if [ $num -eq 0 ]; then
echo "$prog had already stoped ..."
else
echo "$prog is running ..."
fi
}
usage() {
echo "usage: $prog start|stop|status|restart"
echo "options:"
echo " -a allow only given hosts to connect to the server (default is tsung_controller)"
echo " -p use the special port for listen (default is 19999)"
echo " -s use the special erlang's erts bin path for running erlang (default is blank)"
echo " -h display this help and exit"
exit
}
while getopts "a:p:s:h" option
do
case $option in
a) tsung_controller=$optarg;;
p) port=$optarg;;
s) tmp_erl=$optarg
if [ "$optarg" != "" ]; then
if [[ "$optarg" == *"/" ]]; then
special_path=$optarg
else
special_path=$optarg"/"
fi
fi
;;
h) usage;;
*) usage;;
esac
done
shift $(($optind - 1))
case $1 in
start)
prepare
start
;;
stop)
stop
;;
status)
status
;;
restart)
stop
start
;;
*)
usage
;;
esac
总结一下:
- 基于
ncat监听19999端口提供bind shell机制,但限制有限ip可访问 - 动态生成命令过滤脚本
rsh_filter.sh,执行erlang从节点命令
请参考:
客户端连接方案
服务器端已经提供了端口接入并准备好了接收指令,客户端(rsh_client.sh)可以进行连接和交互了:
- 类似ssh客户端接收方式:
rsh_client.sh host/ip command - 完全基于
nc命令,连接远程主机 - 连接成功,发送命令
- 得到相应,流程完成
一样非常少的代码呈现。
#!/bin/sh
port=19999
if [ $# -lt 2 ]; then
echo "invalid number of parameters"
exit 1
fi
remotehost="$1"
command="$2"
if [ "${command}" != "erl" ]; then
echo "invalid command ${command}"
exit 1
fi
shift 2
echo "${command} $*" | /usr/bin/nc ${remotehost} ${port}
erlang主节点如何启动
有了ssh替换方案,那主节点就可以这样启动了:
erl -rsh ~/.tsung/rsh_client.sh -sname foo -setcookie mycookie
比如当tsung需要连接到另外一台服务器上启动从节点时,它最终会翻译成下面命令:
/bin/sh /root/.tsung/rsh_client.sh node_slave erl -detached -noinput -master foo@node_master -sname bar@node_slave -s slave slave_start foo@node_master slave_waiter_0 -setcookie mycookie
客户端脚本rsh_client.sh则最终需要执行连接到服务器、并发送命的命令:
echo "erl -detached -noinput -master foo@node_master -sname bar@node_slave -s slave slave_start foo@node_master slave_waiter_0 -setcookie mycookie" | /usr/bin/nc node_slave 19999
这样就实现了和ssh一样的功能了,很简单吧。
tsung如何切换切换?
为tsung启动添加-r参数指定即可:
tsung -r ~/.tsung/rsh_client.sh -f tsung.xml start
进阶:可指定运行命令路径
rsh_client.sh脚本最后一行修改一下,指定目标服务器erl运行命令:
#!/bin/sh
port=19999
if [ $# -lt 2 ]; then
echo "invalid number of parameters"
exit 1
fi
remotehost="$1"
command="$2"
if [ "${command}" != "erl" ]; then
echo "invalid command ${command}"
exit 1
fi
shift 2
exec echo "/root/.tsung/otp_18/bin/erl $*" | /usr/bin/nc ${remotehost} 19999
上面脚本所依赖的上下文环境可以是这样的,机房服务器操作系统和版本一致,我们把erlang 18.1整个运行时环境在一台机器上已经安装的目录(比如目录名为otp_18),拷贝到远程主机/root/.tsung/目录,相比于安装而言,可以让tsung运行依赖的eralng环境完全可以移植化(portable),一次安装,多次复制。
代码托管地址
本文所谈及代码,都已经托管在github:
后续代码更新、bug修复等,请直接参考该仓库。
小结
简单一套新的替换ssh通道无密钥登陆远程主机c/s模型,虽然完整性上无法与ssh相比,但胜在简单够用,完全满足了当前业务需要,并且其运维成本低,无疑让tsung在复杂服务器内网环境下适应性又朝前多走了半里路。
下一篇将介绍为tsung增加ip直连特性支持,使其分布式网络环境下适应性更广泛一些。
]]>
这里汇集一下影响tsung client创建用户数的各项因素。因为tsung是io密集型的应用,cpu占用一般不大,为了尽可能的生成更多的用户,需要考虑内存相关事宜。
ip & 端口的影响
1. 系统端口限制
linux系统端口为short类型表示,数值上限为65535。假设分配压测业务可用端口范围为1024 - 65535,不考虑可能还运行着其它对外连接的服务,真正可用端口也就是64000左右(实际上,一般为了方便计算,一般直接设定为50000)。换言之,即在一台机器上一个ip,可用同时对外建立64000网络连接。
若是n个可用ip,理论上 64000*n,实际上还需要满足:
- 充足内存支持
- tcp接收/发送缓冲区不要设置太大,tsung默认分配32k(可以修改成16k,一般够用了)
- 一个粗略估算一个连接占用80k内存,那么10万用户,将占用约8g内存
- 为多ip的压测端分配适合的权重,以便承担更多的终端连接
另外还需要考虑端口的快速回收等,可以这样做:
sysctl -w net.ipv4.tcp_syncookies=1
sysctl -w net.ipv4.tcp_tw_reuse=1
sysctl -w net.ipv4.tcp_tw_recycle=1
sysctl -w net.ipv4.tcp_fin_timeout=30
sysctl -w net.ipv4.ip_local_port_range="1024 65535"
sysctl -p
若已经在 /etc/sysctl.conf 文件中有记录,则需要手动修改
作为附加,可设置端口重用:
注意,不要设置下面的可用端口范围:
因为操作系统会自动跳过已经被占用本地端口,而tsung只能够被动通过错误进行可用端口 1继续下一个连接,有些多余。
2. ip和端口组合
每一个client支持多个可用ip地址列表
tsung client从节点开始准备建立网络连接会话时,需要从tsung_controller主节点获取具体的会话信息,其中就包含了客户端连接需要使用到来源{localip, localport}二元组。由tsung_controller主节点完成。
get_user_param(client,config)->
{ok, ip} = choose_client_ip(client),
{ok, server} = choose_server(config#config.servers, config#config.total_server_weights),
cport = choose_port(ip, config#config.ports_range),
{{ip, cport}, server}.
choose_client_ip(#client{ip = iplist, host=host}) ->
choose_rr(iplist, host, {0,0,0,0}).
......
choose_client_ip(#client{ip = iplist, host=host}) ->
choose_rr(iplist, host, {0,0,0,0}).
choose_rr(list, key, _) ->
i = case get({rr,key}) of
undefined -> 1 ; % first use of this key, init index to 1
val when is_integer(val) ->
(val rem length(list)) 1 % round robin
end,
put({rr, key},i),
{ok, lists:nth(i, list)}.
%% 默认不设置 ports_range 会直接返回0
%% 不建议设置 从节点建立到压测服务器连接时,就需要指定从主节点获取到的本机ip地址和端口两元组:
opts = protocol_options(protocol, proto_opts) [{ip, ip},{port,cport}],
......
gen_tcp:connect(server, port, opts, connecttimeout).
3. ip自动扫描特性
若从机单个网卡绑定了多个ip,又懒于输入,可以配置扫描特性:
本质上使用shell方式获取ip地址,并且支持centos 6/7。
/sbin/ip -o -f inet addr show dev eth0
因为扫描比较慢,tsung 1.6.1推出了
ip_range特性支持。
linux系统打开文件句柄限制
系统打开文件句柄,直接决定了可以同时打开的网络连接数量,这个需要设置大一些,否则,你可能会在文件中看到error_connect_emfile类似文件句柄不够使用的警告,建议此值要大于 > n * 64000。
echo "* soft nofile 300000" >> /etc/security/limits.conf
echo "* hard nofile 300000" >> /etc/security/limits.conf
或者,在tsung会话启动脚本文件中明确添加上ulimit -n 300000。
内存的影响
一个网络socket连接占用不多,但上万个或数十万等就不容小觑了,设置不当会导致内存直接成为屏障。
1. tcp接收、发送缓存
tsung默认设置的网络socket发送接收缓冲区为16kb,一般够用了。
以tcp为例,某次我手误为tcp接收缓存赋值过大(599967字节),这样每一个网络了解至少占用了0.6m内存,直接导致在16g内存服务上网络连接数到2万多时,内存告急。
此值会覆盖linux系统设置接收、发送缓冲大小。
粗略的默认值计算,一个网络连接发送缓冲区 接收缓冲区,再加上进程处理连接堆栈占用,约40多k内存,为即计算方便,设定建立一个网络连接消费50k内存。
先不考虑其它因素,若我们想要从机模拟10w个用户,那么当前可用内存至少要剩余:50k * 100000 / 1000k = 5000m = 5g内存。针对一般服务器来讲,完全可满足要求(剩下事情就是要有两个可用ip了)。
2. erlang函数堆栈内存占用
使用erlang程序写的应用服务器,进程要存储堆栈调用信息,进程一多久会占用大量内存,想要服务更多网络连接/任务,需要将不活动的进程设置为休眠状态,以便节省内存,tsung的压测会话信息若包含thinktime时间,也要考虑启用hibernate休眠机制。
值单位秒,默认thinktime超过10秒后自动启动,这里修改为5秒。
xml文件设置需要注意部分
1. 日志等级要调高一些
tsung使用error_logger记录日志,其只适用于真正的异常情况,若当一般业务调试类型日志量过多时,不但耗费了大量内存,网络/磁盘写入速度跟不上生产速度时,会导致进程堵塞,严重会拖累整个应用僵死,因此需要在tsung.xml文件中设置日志等级要高一些,至少默认的notice就很合适。
2. 不要启用dump
dump是一个耗时的行为,因此默认为false,除非很少的压测用户用于调试。
3. 动态属性太多,会导致请求超时
设定一个有状态的场景,用户id储存在文件中,每一次会话请求都要从获取到用户id,压测用户一旦达到百万级别并且用户每秒产生速率过大(比如每秒1000个用户),会经常遇到超时错误:
=error report==== 25-jul-2016::15:14:11 ===
** reason for termination =
** {timeout,{gen_server,call,
[{global,ts_file_server},{get_next_line,userdb}]}}
这是因为,当tsung client遇到setdynvars指令时,会直接请求主机ts_file_server模块,当一时间请求量巨大,可能会造成单一模块处理缓慢,出现超时问题。
怎么办:
- 降低用户每秒产生速率,比如300秒用户生成
- 不用从文件中存储用户id等信息,采用别的方式
如何限流/限速
某些时候,要避免tsung client压测端影响所在服务器网络带宽io太拥挤,需要限制流量,其采用令牌桶算法。
- 值为kb单位每秒
- 目前仅对传入流量生效
阀值计算方式:
{rateconf,sizethresh} = case ratelimit of
token=#token_bucket{} ->
thresh=lists:min([?size_mon_thresh,token#token_bucket.burst]),
{token#token_bucket{last_packet_date=starttime}, thresh};
undefined ->
{undefined, ?size_mon_thresh}
end,
接收传入流量数据,需要计算:
handle_info2({gen_ts_transport, _socket, data}, wait_ack, state=#state_rcv{rate_limit=tokenparam}) when is_binary(data)->
?debugf("data received: size=~p ~n",[size(data)]),
newtokenparam = case tokenparam of
undefined ->
undefined;
#token_bucket{rate=r,burst=burst,current_size=s0, last_packet_date=t0} ->
{s1,_wait}=token_bucket(r,burst,s0,t0,size(data),?now,true),
tokenparam#token_bucket{current_size=s1, last_packet_date=?now}
end,
{newstate, opts} = handle_data_msg(data, state),
newsocket = (newstate#state_rcv.protocol):set_opts(newstate#state_rcv.socket,
[{active, once} | opts]),
case newstate#state_rcv.ack_done of
true ->
handle_next_action(newstate#state_rcv{socket=newsocket,rate_limit=newtokenparam,
ack_done=false});
false ->
timeout = case (newstate#state_rcv.request)#ts_request.ack of
global ->
(newstate#state_rcv.proto_opts)#proto_opts.global_ack_timeout;
_ ->
(newstate#state_rcv.proto_opts)#proto_opts.idle_timeout
end,
{next_state, wait_ack, newstate#state_rcv{socket=newsocket,rate_limit=newtokenparam}, timeout}
end;
下面则是具体的令牌桶算法:
%% @spec token_bucket(r::integer(),burst::integer(),s0::integer(),t0::tuple(),p1::integer(),
%% now::tuple(),sleep::boolean()) -> {s1::integer(),wait::integer()}
%% @doc implement a token bucket to rate limit the traffic: if the
%% bucket is full, we wait (if asked) until we can fill the
%% bucket with the incoming data
%% r = limit rate in bytes/millisec, burst = max burst size in bytes
%% t0 arrival date of last packet,
%% p1 size in bytes of the packet just received
%% s1: new size of the bucket
%% wait: time to wait
%% @end
token_bucket(r,burst,s0,t0,p1,now,sleep) ->
s1 = lists:min([s0 r*round(ts_utils:elapsed(t0, now)),burst]),
case p1 < s1 of
true -> % no need to wait
{s1-p1,0};
false -> % the bucket is full, must wait
wait=(p1-s1) div r,
case sleep of
true ->
timer:sleep(wait),
{0,wait};
false->
{0,wait}
end
end.
小结
以上简单梳理一下影响tsung从机创建用户的各项因素,实际环境其实相当复杂,需要一一对症下药才行。
]]>
接着上文,tsung一旦启动,主从节点之间需要协调分配资源,完成分布式压测任务。
如何启动tsung压测从机
erlang sdk提供了从机启动方式:
slave:start(host, node, opts)
启动从机需要借助于免登陆形式远程终端,比如ssh(后续会讨论ssh存在不足,以及全新的替代品),需要自行配置。
- host属性对应value为从机主机名称:client_100
- node节点名称由tsung_controller组装,类似于
tsung10@client_100 opts表示相关参数- 一个物理机器,可以存在多个tsung从机实例
- 一个tsung从机实例对应一个tsung client
简单翻译一下:slave:start(client_100, 'tsung10@client_100', opts)
从机需要关闭时,就很简单了:
slave:stop(node)
当然若主机中途挂掉,从机也会自动自杀掉自身。
启动tsung client方式
tsung主机启动从机成功,从机和主机就可以erlang节点进程之间进行方法调用和消息传递。潜在要求是,tsung编译后beam文件能够在erlang运行时环境中能够访问到,这个和java classpath一致原理。
rpc:multicall(remotenodes,tsung,start,[],?rpc_timeout)
到此为止,一个tsung client实例成功运行。
- tsung client实例生命周期结束,不会导致从机实例主动关闭
- tsung slave提供了运行时环境,tsung client是业务
- tsung slave和tsung client关系是1 : 1关系,很多时候为了理解方便,不会进行严格区分
压测目标
明白了主从启动方式,下面讨论压测目标,比如50万用户的量,根据给出的压测从机列表,进行任务分配。
压测目标配置
tsung压测xml配置文件,load元素可以配置总体任务生成的信息。
- 定义一个最终压力产生可以持续60分钟压测场景, 上限用户量为50万
- arrivalphase duration属性持续时长表示生成压测用户可消费总体时间60分钟,即为t1
- users元素其属性表示单位时间内(这里单位时间为秒)产生用户数为250个
- 50万用户,将在2000秒(约34分钟)内生成,耗时时长即为t2
- t2小于arrivalphase定义的用户生成阶段持续时间t1
- 若t2时间后(34分钟)后因为产生用户数已经达到了上限,将不再产生新的用户,知道整个压测结束
- 若 t1 小于 t2,则50万用户很难达到,因此t1时间要设置长一些
从节点信息配置
所说从节点也是压测客户端,需要配置clients元素:
......
- 单个client支持多个ip,用于突破单个ip对外建立连接数的限制(后续会讲到)
- xml所定义的一个cliet元素,可能被分裂出若干从机实例(即tsung client),1 : n
根据cpu数量分裂tsung client实例情况
在《tsung documentation》给出了建议,一个cpu一个tsung client实例:
note: even if an erlang vm is now able to handle several cpus (erlang smp), benchmarks shows that it’s more efficient to use one vm per cpu (with smp disabled) for tsung clients. only the controller node is using smp erlang.
therefore, cpu should be equal to the number of cores of your nodes. if you prefer to use erlang smp, add the -s option when starting tsung (and don’t set cpu in the config file).
- 默认策略, 一个tsung client对应一个cpu,若不设置cpu属性,默认值就是1
- 一个cpu对应一个tsung client,n个cpu,n个tsung client
- 共同分担权重,每一个分裂的tsung client权重 weight/n
- 一旦设置cpu属性,无论tsung启动时是否携带
-s参数设置共享cpu,都会- 自动分裂cpu个tsung client实例
- 每一个实例权重为weight/cpu
%% add a new client for each cpu
lists:duplicate(cpu,#client{host = host,
weight = weight/cpu,
maxusers = maxusers})
若要设置单个tsung client实例共享多个cpu(此时不要设置cpu属性啦),需要在tsung启动时添加-s参数,tsung client被启动时,smp属性被设置成auto:
-smp auto a 8
这样从机就只有一个tsung client实例了,不会让人产生困扰。若是临时租借从机,建议启动时使用-s参数,并且要去除cpu属性设置,这样才能够自动共享所有cpu核心。
从机分配用户过多,一样会分裂新的tsung client实例
假设client元素配置maxusers数量为1k,那么实际上被分配数量为10k(压测人数多,压测从机少)时,那么tsung_controller会继续分裂新的tsung client实例,直到10k用户数量完成。
tsung client分配的数量超过自身可服务上限用户时(这里设置的是1k)时,关闭自身。
launcher(_event, state=#launcher{nusers = 0, phases = [] }) ->
?log("no more clients to start, stop ~n",?info),
{stop, normal, state};
launcher(timeout, state=#launcher{nusers = users,
phase_nusers = phaseusers,
phases = phases,
phase_id = id,
started_users = started,
intensity = intensity}) ->
beforelaunch = ?now,
case do_launch({intensity,state#launcher.myhostname,id}) of
{ok, wait} ->
case check_max_raised(state) of
true ->
%% let the other beam starts and warns ts_mon
timer:sleep(?die_delay),
{stop, normal, state};
false->
......
end;
error ->
% retry with the next user, wait randomly a few msec
rndwait = random:uniform(?next_after_failed_timeout),
{next_state,launcher,state#launcher{nusers = users-1} , rndwait}
end.
tsung_controller接收从节点退出通知,但分配总数没有完成,会启动新的tsung client实例(一样先启动从节点,然后再启动tsung client实例)。整个过程串行方式循环,直到10k用户数量完成:
%% start a launcher on a new beam with slave module
handle_cast({newbeam, host, arrivals}, state=#state{last_beam_id = nodeid, config=config, logdir = logdir}) ->
args = set_remote_args(logdir,config#config.ports_range),
seed = config#config.seed,
node = remote_launcher(host, nodeid, args),
case rpc:call(node,tsung,start,[],?rpc_timeout) of
{badrpc, reason} ->
?logf("fail to start tsung on beam ~p, reason: ~p",[node,reason], ?err),
slave:stop(node),
{noreply, state};
_ ->
ts_launcher_static:stop(node), % no need for static launcher in this case (already have one)
ts_launcher:launch({node, arrivals, seed}),
{noreply, state#state{last_beam_id = nodeid 1}}
end;
tsung client分配用户数
一个tsung client分配的用户数,可以理解为会话任务数。tsung以终端可以模拟的用户为维度进行定义压测。
所有配置tsung client元素(设置m1)权重相加之和为总权重totalweight,用户总数为maxmember,一个tsung client实例(总数设为m2)分配的模拟用户数可能为:
maxmember*(weight/totalweight)
需要注意:
- m2 >= m1
- 若压测阶段duration值过小,小于最终用户50万用户按照每秒250速率耗时时间,最终分配用户数将小于期望值
只有一台物理机的tsung master启动方式
没有物理从机,主从节点都在一台机器上,需要设置use_controller_vm="true"。相比tsung集群,单一节点tsung启动就很简单,主从之间不需要ssh通信,直接内部调用。
local_launcher([host],logdir,config) ->
?logf("start a launcher on the controller beam ~p~n", [host], ?notice),
logdirenc = encode_filename(logdir),
%% set the application spec (read the app file and update some env. var.)
{ok, {_,_,appspec}} = load_app(tsung),
{value, {env, oldenv}} = lists:keysearch(env, 1, appspec),
newenv = [ {debug_level,?config(debug_level)}, {log_file,logdirenc}],
repkeyfun = fun(tuple, list) -> lists:keyreplace(element(1, tuple), 1, list, tuple) end,
env = lists:foldl(repkeyfun, oldenv, newenv),
newappspec = lists:keyreplace(env, 1, appspec, {env, env}),
ok = application:load({application, tsung, newappspec}),
case application:start(tsung) of
ok ->
?log("application started, activate launcher, ~n", ?info),
application:set_env(tsung, debug_level, config#config.loglevel),
case config#config.ports_range of
{min, max} ->
application:set_env(tsung, cport_min, min),
application:set_env(tsung, cport_max, max);
undefined ->
""
end,
ts_launcher_static:launch({node(), host, []}),
ts_launcher:launch({node(), host, [], config#config.seed}),
1 ;
{error, reason} ->
?logf("can't start launcher application (reason: ~p) ! aborting!~n",[reason],?emerg),
{error, reason}
end.
用户生成控制
用户和会话控制
每一个tsung client运行着一个ts_launch/ts_launch_static本地注册模块,掌控终端模拟用户生成和会话控制。
- 向主节点ts_config_server请求隶属于当前从机节点的会话信息
- 启动模拟终端用户ts_client
- 控制下一个模拟终端用户ts_client需要等待时间,也是控制从机用户生成速度
- 执行是否需要切换到新的阶段会话
- 控制模拟终端用户是否已经达到了设置的
maxusers上限
- 到上限,自身使命完成,关闭自身
- 源码位于 tsung-1.6.0/src/tsung 目录下
主机按照xml配置生成全局用户产生速率,从机按照自身权重分配的速率进行单独控制,这也是任务分解的具体呈现。
用户生成速度控制
在tsung中用户生成速度称之为强度,根据所配置的load属性进行配置
关键属性:
interarrival,生成压测用户的时间间隔arrivalrate:单位时间内生成用户数量- 两者最终都会被转换为生成用户强度系数值是0.25
- 这个是总的强度值,但需要被各个tsung client分解
parse(element = #xmlelement{name=users, attributes=attrs},
conf = #config{arrivalphases=[cura | alist]}) ->
max = getattr(integer,attrs, maxnumber, infinity),
?logf("maximum number of users ~p~n",[max],?info),
unit = getattr(string,attrs, unit, "second"),
intensity = case {getattr(float_or_integer,attrs, interarrival),
getattr(float_or_integer,attrs, arrivalrate) } of
{[],[]} ->
exit({invalid_xml,"arrival or interarrival must be specified"});
{[], rate} when rate > 0 ->
rate / to_milliseconds(unit,1);
{interarrival,[]} when interarrival > 0 ->
1/to_milliseconds(unit,interarrival);
{_value, _value2} ->
exit({invalid_xml,"arrivalrate and interarrival can't be defined simultaneously"})
end,
lists:foldl(fun parse/2,
conf#config{arrivalphases = [cura#arrivalphase{maxnumber = max,
intensity=intensity}
|alist]},
element#xmlelement.content);
tsung_controller对每一个tsung client生成用户强度分解为 clientintensity = phaseintensity * weight / totalweight,而1000 * clientintensity就是易读的每秒生成用户速率值。
get_client_cfg(arrival=#arrivalphase{duration = duration,
intensity= phaseintensity,
curnumber= curnumber,
maxnumber= maxnumber },
{totalweight,client,islast} ) ->
weight = client#client.weight,
clientintensity = phaseintensity * weight / totalweight,
nusers = round(case maxnumber of
infinity -> %% only use the duration to set the number of users
duration * clientintensity;
_ ->
tmpmax = case {islast,curnumber == maxnumber} of
{true,_} ->
maxnumber-curnumber;
{false,true} ->
0;
{false,false} ->
lists:max([1,trunc(maxnumber * weight / totalweight)])
end,
lists:min([tmpmax, duration*clientintensity])
end),
?logf("new arrival phase ~p for client ~p (last ? ~p): will start ~p users~n",
[arrival#arrivalphase.phase,client#client.host, islast,nusers],?notice),
{arrival#arrivalphase{curnumber=curnumber nusers}, {clientintensity, nusers, duration}}.
前面讲到每一个tsung client被分配用户数公式为:min(duration * clientintensity, maxnumber * weight / totalweight):
- 避免总人数超出限制
- 阶段phase持续时长所产生用户数和tsung client分配用户数不至于产生冲突,一种协调策略
再看一下launch加载一个终端用户时,会自动根据当前分配用户生成压力系数获得ts_stats:exponential(intensity)下一个模拟用户产生等待生成的最长时间,单位为毫秒。
do_launch({intensity, myhostname, phaseid})->
%%get one client
%%set the profile of the client
case catch ts_config_server:get_next_session({myhostname, phaseid} ) of
{'exit', {timeout, _ }} ->
?log("get_next_session failed (timeout), skip this session !~n", ?err),
ts_mon:add({ count, error_next_session }),
error;
{ok, session} ->
ts_client_sup:start_child(session),
x = ts_stats:exponential(intensity),
?debugf("client launched, wait ~p ms before launching next client~n",[x]),
{ok, x};
error ->
?logf("get_next_session failed for unexpected reason [~p], abort !~n", [error],?err),
ts_mon:add({ count, error_next_session }),
exit(shutdown)
end.
ts_stats:exponential逻辑引入了指数计算:
exponential(param) ->
-math:log(random:uniform())/param.
继续往下看吧,隐藏了部分无关代码:
launcher(timeout, state=#launcher{nusers = users,
phase_nusers = phaseusers,
phases = phases,
phase_id = id,
started_users = started,
intensity = intensity}) ->
beforelaunch = ?now,
case do_launch({intensity,state#launcher.myhostname,id}) of
{ok, wait} ->
...
{continue} ->
now=?now,
launchduration = ts_utils:elapsed(beforelaunch, now),
%% to keep the rate of new users as expected,
%% remove the time to launch a client to the next
%% wait.
newwait = case wait > launchduration of
true -> trunc(wait - launchduration);
false -> 0
end,
?debugf("real wait = ~p (was ~p)~n", [newwait,wait]),
{next_state,launcher,state#launcher{nusers = users-1, started_users=started 1} , newwait}
...
error ->
% retry with the next user, wait randomly a few msec
rndwait = random:uniform(?next_after_failed_timeout),
{next_state,launcher,state#launcher{nusers = users-1} , rndwait}
end.
下一个用户生成需要等待wait - launchduration毫秒时间。
给出一个采样数据,只有一个从机,并且用户产生速度1秒一个,共产生10个用户:
采集日志部分,记录了wait时间值,其实总体时间还需要加上launchduration(虽然这个值很小):
ts_launcher:(7:<0.63.0>) client launched, wait 678.5670934164623 ms before launching next client
ts_launcher:(7:<0.63.0>) client launched, wait 810.2982455546687 ms before launching next client
ts_launcher:(7:<0.63.0>) client launched, wait 1469.2208436232288 ms before launching next client
ts_launcher:(7:<0.63.0>) client launched, wait 986.7202548184069 ms before launching next client
ts_launcher:(7:<0.63.0>) client launched, wait 180.7484423006169 ms before launching next client
ts_launcher:(7:<0.63.0>) client launched, wait 1018.9190235965457 ms before launching next client
ts_launcher:(7:<0.63.0>) client launched, wait 1685.0156394273606 ms before launching next client
ts_launcher:(7:<0.63.0>) client launched, wait 408.53992361334065 ms before launching next client
ts_launcher:(7:<0.63.0>) client launched, wait 204.40900996137086 ms before launching next client
ts_launcher:(7:<0.63.0>) client launched, wait 804.6040921461512 ms before launching next client
总体来说,每一个用户生成间隔间不是固定值,是一个大约值,有偏差,但接近于目标设定(1000毫秒生成一个用户标准间隔)。
执行模拟终端用户会话流程
关于会话的说明:
- 一个session元素中的定义一系列请求-响应等交互行为称之为一次完整会话
- 一个模拟用户需要执行一次完整会话,然后生命周期完成,然后结束
模拟终端用户模块是ts_client(状态机),挂载在ts_client_sup下,由ts_launcher/ts_launcher_static调用ts_client_sup:start_child(session)启动,是压测任务的最终执行者,承包了所有脏累差的活:
- 所有下一步需要执行的会话指令都需要向主机的
ts_config_server请求
- 执行会话指令
- 具体协议调用相应协议插件,比如ts_mqtt组装会话消息
- 建立网络socket连接,封装众多网络通道
- 发送请求数据,处理响应
- 记录并发送监控数据和日志
 

小结
简单梳理主从之间启动方式,从机数量分配策略,以具体压测任务如何在从机上分配和运行等内容。

]]>tsung笔记之主从模型篇 http://www.blogjava.net/yongboy/archive/2016/07/23/431294.htmlnieyong nieyong sat, 23 jul 2016 03:56:00 gmt http://www.blogjava.net/yongboy/archive/2016/07/23/431294.html http://www.blogjava.net/yongboy/comments/431294.html http://www.blogjava.net/yongboy/archive/2016/07/23/431294.html#feedback 0 http://www.blogjava.net/yongboy/comments/commentrss/431294.html http://www.blogjava.net/yongboy/services/trackbacks/431294.html 前言
本篇讲解tsung大致功能组成、结构,以及主从模型,以便总体上掌握。
总体组成
 

tsung_controller 和 tsung 这两个模块,负责分布式压测的核心功能。
代码组成
从代码层次梳理一下tsung项目功能组成结构,便于一目了然,方便直接索引。
 

主从模型一览
设定环境为分布式环境下tsung集群,下面简单梳理一下主、从节点启动流程。
 

流程大致说明:
- 主节点(tsung_controller)通过ssh或其它远程终端(后面会讲到操作更为轻量的完全替代ssh方式)连接到从服务器启动tsung从节点运行时环境
- 主节点rpc批量启动tsung client进程
- 主节点为每一个从节点启动会话监控,控制会话速度,开启ts_client模拟终端
- 从节点请求主节点具体业务进程,获取会话指令以及会话具体内容
- 从节点建立到目标压测服务器的socket网络连接,开始会话
- 主节点可以通过ssh/其它终端方式连接到目标压测服务器,启动从节点,然后收集数据(可选,具体细节,后续文字会讲到)
这种模型下:
- 全局严格控制模拟终端用户生成总量和生成速度
- 主节点动态管理从节点生命周期,从生到死,并且掌握着所有会话细节,全局掌控
- 从节点很轻,所有需要的会话指令,都必须请求主节点获得
主从之间交互流程
下面一张图简单说明了主从之间核心模块交互流程,虽然粗略,核心点也算是涉及到了。
 

后面会对具体协议部分有更为详细论述。
一次压测回话(ts_client)工作流程
其实是承接上一个流程图,已经启动了一个ts_client模块,即执行一个完整生命周期会话模拟终端。它的开启依赖于tsung controller启动ts_launch/ts_launch_static模块。
大致流程图如下:
 

会话什么时候结束
- 针对从节点上,(一个终端用户的)一次完整会话(session):
- 请求主节点ts_config模块,获取会话session信息,包含一次会话需要完成任务总数count
- 从节点ts_client 每执行一次事件,任务总数count减1
- 当count值为0时,说明任务执行完毕,ts_client生命周期圆满,一次完整会话结束
- 从节点所分配的所有会话都结束了,表示从节点生命周期也会结束
- 主节点控制的所有从节点都结束了,即所有会话都一一完成,那么整体压测也结束了,整个压测流程结束
小结
基于erlang天生分布式基因支持,从节点的生死存亡完全受tsung主节点的控制,按需创建,任务完成结束,主从协调行云流水般顺畅。
嗯,后面将介绍主从实现的一些细节。

]]> tsung笔记之开篇 http://www.blogjava.net/yongboy/archive/2016/07/22/431291.htmlnieyong nieyong fri, 22 jul 2016 07:36:00 gmt http://www.blogjava.net/yongboy/archive/2016/07/22/431291.html http://www.blogjava.net/yongboy/comments/431291.html http://www.blogjava.net/yongboy/archive/2016/07/22/431291.html#feedback 1 http://www.blogjava.net/yongboy/comments/commentrss/431291.html http://www.blogjava.net/yongboy/services/trackbacks/431291.html 前言
有测试驱动的开发模式,目的在于确保业务层面功能是准确的,每一次新增、修改等动作确保都不会影响到现有功能。功能开发完成了,需要部署到线上,系统能够承载多大的用户量呢,这时候就需要借助于性能压测,也称之为压力测试,界定系统能够承载具体容量上限,从容应对业务的运营需要,扩容或缩容,心中有底。
工欲善其事,必先利其器。掌握一种压测工具,并切实应用到实践环境中,并以此不断迭代,压力测试驱动推动所开发后端应用处理性能逐渐完善。
目前成熟的支持支持tcp、http等连接通道的压测工具不少,以前接触过apache jmeter,后面又接触过tsung,因为在实际环境下使用比较多,支持丰富的业务场景定义,并且可扩展性强,因此tsung强力推荐之。
为什么要选择tsung
- 基于erlang,并发处理性能好,可以模拟足够多海量用户,只要你有足够多的机器
- 受益于erlang,天然支持分布式,很欢快的运行在一个集群中
- 支持协议众多 webdav/webscoket/mqtt/mysql/pgsql/shell/aqmp/jabber/xmpp/ldap 等
- 传输通道支持 tcp/udp/ssl,更底层支持ipv4/ipv6
- 支持单机绑定多个ip:无论是虚拟ip,还是物理网卡绑定ip,可以突破单机端口65535的限制,扩展尽可能多的网络连接出口地址
- 支持监控被压测的服务器,通过erlang agent/snmp/munin
- 压测细节xml可配置,这是一个完全基于情景的压力测试行为清单,依赖于你的想象,呈现完整业务的表达
- 场景可以是动态的,来自于文件、代码或者服务器响应可以构成下一个请求的参数,这就是可编程的请求嘛
- 行为可以混搭,回话可以在不同场景中,按照不同的行为规范各自平行进行
- 休眠,或暂停机制,是可以随机的,亲
- 压测用户产生方式,动态有序或随机
总之,tsung是一款开源的高性能分布式压力测试工具,支持可编程的情景化测试方案,要向发挥它的特性,依赖于人们的想象力和创造性。
为什么要压力测试驱动呢 ?
软件/系统架构往往着眼于总体结构,这个可以是一个逐渐完善的过程。这种自我的不断完善的驱动往往来自于实践、线上考验。而压力测试可以提供一种推动,尽心尽力暴露着架构在性能容量存在的一些不足和缺陷,促使着向着更好的方向发展。
系统的构建依赖于具体参与执行的人,就算是一群资深的工程师,业务上每一次功能的快速更迭、任何潜在局部修改都会导致影响、拖垮整体性能,这就是人们常说的 ”“,牵一发而动全身。
如何提早感知并且提早修复,这就需要压力测试的驱动,并且压力测试应该成为一个常规化的例行行为,日常化的动作。在每一次修改之后,都要过一轮的压测的碾压之后,提供当前后端应用处理的性能、容量等具体指标,用于指导后续业务上线业务的开展。
实际操作上的建议
在一般互联网公司,一般线上程序修改后之后,需要经过qa团队/部门全部功能回归、校验之后才能够上线,往往缺少压测环节,因为他/她们并不保证系统处理性能和容量是否恶化,系统的性能建立在系统总体的功能上,如何避免在性能上出现”牵一发而动全身“,建议有条件的qa同学/团队考虑增加性能压测环节,功能 性能双重回归,修改影响点清晰、透明化。
笔记列表
本系列笔记,基于tsung-1.6.0源码基础上分析,运行环境为linux centos 6。
笔记列表:
- tsung笔记之主从模型篇
- tsung笔记之主从资源协调篇
- tsung笔记之压测端资源限制篇
- tsung笔记之分布式增强跳出ssh羁绊篇
- tsung笔记之ip直连支持篇
- tsung笔记之监控数据收集篇
- tsung笔记之插件编写篇
- tsung笔记之100万用户压测执行步骤篇
- tsung笔记之ip地址和端口限制突破篇
为了方便理解,一些用词说明:
- 主节点,也称之为master node,指的是运行tsung_controller的应用服务实例,运行tsung启动应用自动产生“tsung_controller@机器名/ip”节点名称,一般使用过erlang的同学会很明白
- 从节点,即tsung client应用实例,对应 tsung/src/tsung 项目代码,由tsung_controller主节点控制启动、关闭、任务分配等
小结
参与一个实时性交互强的项目,从一开始单机支撑不够1万用户、平均请求响应时间约900毫秒,到目前混合部署的单机支撑50万用户、平均响应时间为16毫秒,这个过程中tsung不断的压测推动着架构逐渐稳定、系统承载容量、qps优化等完全达标。这是一个压力测试驱动性能改进的流程,每一步的改进能够得到正向反馈。
这一系列笔记,所谈核心是tsung,无论是认知还是改进,最终都是为了理解利器的方方面面,方便着手于实践环境中,压测所带来的能量能够驱动我们的程序/服务性能提升、稳定运行,进而更好方便我们进行容量规划、线上部署等。

]]>